Thoughts on founding open-access journals
November 21st, 2013
 |
| … altogether too much concern with the contents of the journal’s spine text… “reference” image by flickr user Sara S. used by permission. |
Precipitated by a recent request to review some proposals for new open-access journals, I spent some time gathering my own admittedly idiosyncratic thoughts on some of the issues that should be considered when founding new open-access journals. I make them available here. Good sources for more comprehensive information on launching and operating open-access journals are SPARC’s open-access journal publishing resource index and the Open Access Directories guides for OA journal publishers.
Unlike most of my posts, I may augment this post over time, and will do so without explicit marking of the changes. Your thoughts on additions to the topics below—via comments or email—are appreciated. A version number (currently version 1.0) will track the changes for reference.
It is better to flip a journal than to found one
The world has enough journals. Adding new open-access journals as alternatives to existing ones may be useful if there are significant numbers of high quality articles being generated in a field for which there is no reasonable open-access venue for publication. Such cases are quite rare, especially given the rise of open-access “megajournals” covering the sciences (PLoS ONE, Scientific Reports, AIP Advances, SpringerPlus, etc.), and the social sciences and humanities (SAGE Open). Where there are already adequate open-access venues (even if no one journal is “perfect” for the field), scarce resources are probably better spent elsewhere, especially on flipping journals from closed to open access.
Admittedly, the world does not have enough open-access journals (at least high-quality ones). So if it is not possible to flip a journal, founding a new one may be a reasonable fallback position, but it is definitely the inferior alternative.
Licensing should be by CC-BY
As long as you’re founding a new journal, its contents should be as open as possible consistent with appropriate attribution. That exactly characterizes the CC-BY license. It’s also a tremendously simple approach. Once the author grants a CC-BY license, no further rights need be granted to the publisher. There’s no need for talk about granting the publisher a nonexclusive license to publish the article, etc., etc. The CC-BY license already allows the publisher to do so. There’s no need to talk about what rights the author retains, since the author retains all rights subject to the nonexclusive CC-BY license. I’ve made the case for a CC-BY license at length elsewhere.
It’s all about the editorial board
The main product that a journal is selling is its reputation. A new journal with no track record needs high quality submissions to bootstrap that reputation, and at the start, nothing is more convincing to authors to submit high quality work to the journal than its editorial board. Getting high-profile names somewhere on the masthead at the time of the official launch is the most important thing for the journal to do. (“We can add more people later” is a risky proposition. You may not get a second chance to make a first impression.)
Getting high-profile names on your board may occur naturally if you use the expedient of flipping an existing closed-access journal, thereby stealing the board, which also has the benefit of acquiring the journal’s previous reputation and eliminating one more subscription journal.
Another good idea for jumpstarting a journal’s reputation is to prime the article pipeline by inviting leaders in the field to submit their best articles to the journal before its official launch, so that the journal announcement can provide information on forthcoming articles by luminaries.
Follow ethical standards
Adherence to the codes of conduct of the Open Access Scholarly Publishers Association (OASPA) and the Committee on Publication Ethics (COPE) should be fundamental. Membership in the organizations is recommended; the fees are extremely reasonable.
You can outsource the process
There is a lot of interest among certain institutions to found new open-access journals, institutions that may have no particular special expertise in operating journals. A good solution is to outsource the operation of the journal to an organization that does have special expertise, namely, a journal publisher. There are several such publishers who have experience running open-access journals effectively and efficiently. Some are exclusively open-access publishers, for example, Co-Action Publishing, Hindawi Publishing, Ubiquity Press. Others handle both open- and closed-access journals: HighWire Press, Oxford University Press, ScholasticaHQ, Springer/BioMed Central, Wiley. This is not intended as a complete listing (the Open Access Directory has a complementary offering), nor in any sense an endorsement of any of these organizations, just a comment that shopping the journal around to a publishing partner may be a good idea. Especially given the economies of scale that exist in journal publishing, an open-access publishing partner may allow the journal to operate much more economically than having to establish a whole organization in-house.
Certain functionality should be considered a baseline
Geoffrey Pullum, in his immensely satisfying essays “Stalking the Perfect Journal” and “Seven Deadly Sins in Journal Publishing”, lists his personal criteria in journal design. They are a good starting point, but need updating for the era of online distribution. (There is altogether too much concern with the contents of the journal’s spine text for instance.)
- Reviewing should be anonymous (with regard to the reviewers) and blind (with regard to the authors), except where a commanding argument can be given for experimenting with alternatives.
- Every article should be preserved in one (or better, more than one) preservation system. CLOCKSS, Portico1, a university or institutional archival digital repository are good options.
- Every article should have complete bibliographic metadata on the first page, including license information (a simple reference to CC-BY; see above), and (as per Pullum) first and last page numbers.
- The journal should provide DOIs for its articles. OASPA membership is an inexpensive way to acquire the ability to assign DOIs. An article’s DOI should be included in the bibliographic metadata on the first page.
There’s additional functionality beyond this baseline that would be ideal, though the tradeoff against the additional effort required would have to be evaluated.
- Provide article-level metrics, especially download statistics, though other “altmetrics” may be helpful.
- Provide access to the articles in multiple formats in addition to PDF: HTML, XML with the NLM DTD.
- Provide the option for readers to receive alerts of new content through emails and RSS feeds.
- Encourage authors to provide the underlying data to be distributed openly as well, and provide the infrastructure for them to do so.
Take advantage of the networked digital era
Many journal publishing conventions of long standing are no longer well motivated in the modern era. Here are a few examples. They are not meant to be exhaustive. You can probably think of others. The point is that certain standard ideas can and should be rethought.
- There is no longer any need for “issues” of journals. Each article should be published as soon as it is finished, no later and no sooner. If you’d like, an “issue” number can be assigned that is incremented for each article. (Volumes, incremented annually, are still necessary because many aspects of the scholarly publishing and library infrastructure make use of them. They are also useful for the purpose of characterizing a bolus of content for storage and preservation purposes.)
- Endnotes, a relic of the day when typesetting was a complicated and fraught process that was eased by a human being not having to determine how much space to leave at the bottom of a page for footnotes, should be permanently retired. Footnotes are far easier for readers (which is the whole point really), and computers do the drudgery of calculating the space for them.
- Page limits are silly. In the old physical journal days, page limits had two purposes. They were necessary because journal issues came in quanta of page signatures, and therefore had fundamental physical limits to the number of pages that could be included. A network-distributed journal no longer has this problem. Page limits also serve the purpose of constraining the author to write relatively succinctly, easing the burden on reviewer and (eventually) reader. But for this purpose the page is not a robust unit of measurement of the constrained resource, the reviewers’ and the readers’ attention. One page can hold anything from a few hundred to a thousand or more words. If limits are to be required, they should be stated in appropriate units such as the number of words. The word count should not include figures, tables, or bibliography, as they impinge on readers’ attention in a qualitatively different way.
- Author-date citation is far superior to numeric citation in every way except for the amount of space and ink required. Now that digital documents use no physical space or ink, there is no longer an excuse for numeric citations. Similarly, ibid. and op. cit. should be permanently retired. I appreciate that different fields have different conventions on these matters. That doesn’t change the fact that those fields that have settled on numeric citations or ibidded footnotes are on the wrong side of technological history.
- Extensive worry about and investment in fancy navigation within and among the journal’s articles is likely to be a waste of time, effort, and resources. To first approximation, all accesses to articles in the journal will come from sites higher up in the web food chain—the Google’s and Bing’s, the BASE’s and OAIster’s of the world. Functionality that simplifies navigation among articles across the whole scholarly literature (cross-linked DOIs in bibliographies, for instance, or linked open metadata of various sorts) is a different matter.
Think twice
In the end, think long and hard about whether founding a new open-access journal is the best use of your time and your institution’s resources in furthering the goals of open scholarly communication. Operating a journal is not free, in cash and in time. Perhaps a better use of resources is making sure that the academic institutions and funders are set up to underwrite the existing open-access journals in the optimal way. But if it’s the right thing to do, do it right.
- A caveat on Portico’s journal preservation service: The service is designed to release its stored articles when a “trigger event” occurs, for instance, if the publisher ceases operations. Unfortunately, Portico doesn’t release the journal contents openly, but only to its library participants, even for OA journals. However, if the articles were licensed under CC-BY, any participating library could presumably reissue them openly.↩
Lessons from the faux journal investigation
October 15th, 2013
 |
| …what 419 scams are to banking… “scams upon scammers” image by flickr user Daniel Mogford used by permission. |
Investigative science journalist John Bohannon[1] has a news piece in Science earlier this month about the scourge of faux open-access journals. I call them faux journals (rather than predatory journals), since they are not real journals at all. They display the trappings of a journal, promising peer-review and other services, but do not deliver; they perform no peer review, and provide no services, beyond posting papers and cashing checks for the publication fees. They are to scholarly journal publishing what 419 scams are to banking.
We’ve known about this practice for a long time, and Jeffrey Beall has done yeoman’s work codifying it informally. He has noted a recent dramatic increase in the number of publishers that appear to be engaged in the practice, growing by an order of magnitude in 2012 alone.
In the past, I’ve argued that the faux journal problem, while unfortunate, is oversold. My argument was that the existence of these faux journals costs clued-in researchers, research institutions, and the general public nothing. The journals don’t charge subscription fees, and we don’t submit articles to them so don’t pay their publication fees. Caveat emptor ought to handle the problem, I would have thought.
But I’ve come to understand over the past few years that the faux journal problem is important to address. The number of faux journals has exploded, and despite the fact that the faux journals tend to publish few articles, their existence crowds out attention to the many high-quality open-access journals. Their proliferation provides a convenient excuse to dismiss open-access journals as a viable model for scholarly publishing. It is therefore important to get a deeper and more articulated view of the problem.
My views on Bohannon’s piece, which has seen a lot of interest, may therefore be a bit contrarian among OA aficionados, who are quick to dismiss the effort as a stunt or to attribute hidden agendas. Despite some flaws (which have been widely noted and are discussed in part below), the study well characterizes and provides a far richer understanding of the faux OA journal problem. Bohannon provides tremendous texture to our understanding of the problem, far better than the anecdotal and unsystematic approaches that have been taken in the past.
His study shows that even in these early days of open-access publishing, many OA journals are doing an at least plausible job of peer review. In total, 98 of the 255 journals that came to a decision on the bogus paper (about 38%) rejected it. It makes clear that the problem of faux journal identification may not be as simple as looking at superficial properties of journal web sites. About 18% of the journals from Beall’s list of predatory publishers actually performed sufficient peer review to reject the bogus articles outright.
Just as clearly, the large and growing problem of faux journals — so easy to set up and so inexpensive to run — requires all scholars to pay careful attention to the services that journals provide. This holds especially for open-access journals, which are generally newer, with shorter track records, and for which the faux journal fraud has proliferated in a short time much faster than appropriate countermeasures can be deployed. The experiment provides copious data on where the faux journals tend to operate from, where they bank, where their editors are.
Bohannon should also be commended for providing his underlying data open access, which will allow others to do even more detailed analysis.
As with all studies, there are some aspects that require careful interpretation.
First, the experiment did not test subscription journals. All experimenters, Bohannon included, must decide how to deploy scarce resources; his concentrating on OA journals, where the faux journal problem is well known to be severe, is reasonable for certain purposes. However, as many commentators have noted, it does prevent drawing specific conclusions comparing OA with subscription journals. Common sense might indicate that OA journals, whose revenues rely more directly on the number of articles published, have more incentive to fraudulently accept articles without review, but the study unfortunately can’t directly corroborate this, and as in so many areas, common sense may be wrong. We know, for instance, that many OA journals seem to operate without the rapacity to accept every article that comes over the transom, and that there are countervailing economic incentives for OA journals to maintain high quality. Journals from 98 publishers — including the “big three” OA publishers Public Library of Science, Hindawi, and BioMed Central — all rejected the bogus paper, and more importantly, a slew of high-quality journals throughout many fields of scholarship are conducting exemplary peer review on every paper they receive. (Good examples are the several OA journals in my own research area of artificial intelligence — JMLR, JAIR, CL — which are all at the top of the prestige ladder in their fields.) Conversely, subscription publishers also may have perverse incentives to accept papers: Management typically establish goals for the number of articles to be published per year; they use article count statistics in marketing efforts; their regular founding of new journals engenders a need for a supply of articles so as to establish their contribution to the publisher’s stable of bundled journals; and many subscription journals especially in the life sciences charge author-side fees as well. Nonetheless, it would be unsurprising if the acceptance rate for the bogus articles would have been lower for subscription journal publishers given what we know about the state of faux journals. (Since there are many times more subscription journals than OA journals, it’s unclear how the problem would have compared in terms of absolute numbers of articles.) Hopefully, future work can clear up this problem with controls.
Second, the experiment did not test journals charging no author-side fees, which is currently the norm among OA journals. That eliminates about 70% of the OA journals, none of which have any incentive whatsoever to accept articles for acceptance’s sake. Ditto for journals that gain their revenue through submission fees instead of publication fees, a practice that I have long been fond of.
Third, his result holds only for journal publishing in the life sciences. (Some people in the life sciences need occasional reminding that science research is not coextensive with life sciences research, and that scholarly research is not coextensive with science research.) I suspect the faux journal problem is considerably lower outside of the life sciences. It is really only in the life sciences where there is long precedent for author-side charges and deep pockets to pay those charges in much of the world, so that legitimate OA publishers can rely on being paid for their services. This characteristic of legitimate life sciences OA journals provides the cover for the faux journals to pretend to operate in the same way. In many other areas of scholarship, OA journals do not tend to charge publication fees as the researcher community does not have the same precedent.
Finally, and most importantly, since the study reports percentages by publisher, rather than by journal or by published article, the results may overrepresent the problem from the reader’s point of view. Just because 62% of the tested publishers[2] accepted the bogus paper doesn’t mean the problem covers that percentage of OA publishing or even of life sciences APC-charging OA publishing. The faux publishers may publish a smaller percentage of the journals (though the faux publishers’ tactic of listing large numbers of unstaffed journals may lead to the opposite conclusion). More importantly, those publishers may cover a much smaller fraction of OA-journal-published papers. (Anyone who has spent any time surfing the web sites of faux journal publishers knows their tendency to list many journals with very few articles. Even fewer if you eliminate the plagiarized articles that faux publishers like to use to pad their journals.) So the vast majority of OA-published articles are likely to be from the 38% “good” journals. This should be determinable from Bohannon’s data — again thanks to his openness — and it would be useful to carry out the calculation, to show that the total number of OA-journal articles published by the faux publishers account for a small fraction of the OA articles published in all of the OA journals of all of the publishers in the study. I expect that’s highly likely.[3]
Bohannon has provided a valuable service, and his article is an important reminder, like the previous case of the faux Australasian Journals, that journal publishers do not always operate under selfless motivations. It behooves authors to take this into account, and it behooves the larger scientific community to establish infrastructure for helping researchers by systematically and fairly tracking and publicizing information about journals that can help its members with their due diligence.
- In the interest of full disclosure, I mention that I am John Bohannon’s sponsor in his role as an Associate (visiting researcher) of the School of Engineering and Applied Sciences at Harvard. He conceived, controlled, and carried out his study independently, and was in no sense under my direction. Though I did have discussions with him about his project, including on some of the topics discussed below, the study and its presentation were his alone. ↩
- It is also worth noting that by actively searching out lists of faux journals (Beall’s list) to add to a more comprehensive list (DOAJ), Bohannon may have introduced skew into the data collection. The attempt to be even more comprehensive than DOAJ is laudable, but the method chosen means that even more care must be taken in interpreting the results. If we look only at the DOAJ-listed journals that were tested, the acceptance rate drops from 62% to 45%. If we look only at OASPA members subject to the test, who commit to a code of conduct, then by my count the acceptance rate drops to 17%. That’s still too high of course, but it does show that the cohort counts, and adding in Beall’s list but not OASPA membership (for instance) could have an effect. ↩
- In a videotaped live chat, Michael Eisen has claimed that this is exactly the case. ↩
Ecumenical open access and the Finch Report principles
July 10th, 2013
 |
| …myopic… “myopic” image by flickr user haglundc used by permission. |
I was invited by the British Academy for the Humanities and Social Sciences to write a piece on last year’s report “Accessibility, sustainability, excellence: How to expand access to research publications” by the Working Group on Expanding Access to Published Research Findings (the “Finch Report”). The paper is part of a collection on “Debating Open Access“.
The Finch Report has been broadly criticized by open access advocates for several reasons, especially its preferring gold to green OA, and doing so to such an extent that its proposals actually incentivize publishers to make their publication agreements less OA-friendly. In fact, there’s evidence that publishers are already acting on those incentives.
I took the opportunity to concentrate my remarks on one of the underemphasized problems with the Finch Report recommendations, their conflation of two quite different notions of gold open access: open-access journals and hybrid journals. The two models work quite differently from a market perspective, and ignoring the distinctions leads to incredibly bad incentives in the resulting recommendations.
The published version of the paper has been made available by the British Academy under a CC-by-nc-nd license. I’ve duplicated it below, under a CC-by license as with all Occasional Pamphlet postings.
The Working Group on Expanding Access to Published Research Findings first convened in 2011 at the behest of David Willetts, the UK Minister for Universities and Science, to “examine how most effectively to expand access to the quality-assured published outputs of research; and to propose a programme of action to that end.” The group consisted of representatives of various of the stakeholder communities related to scholarly publishing, and was chaired by Janet Finch. Their final report (Finch 2012) makes concrete policy recommendations for UK research funders to implement, and has been the basis for the policies being set by the Research Councils UK (RCUK).
There is much to like in the Finch Report on open access. The primary recommendations have to do with directly providing for open access to scholarly articles funded by UK research agencies.1 The report appropriately outlines four desiderata that need to be optimised to this end (Finch 2012, 17):
- Access
- The report takes as given the importance and desirability of open access to the scholarly literature.
- Usability
- It highlights the importance of a broad range of use rights, not just the ability for researchers to read the articles, but all other kinds of reuse rights as well.
- Quality
- The scholarly publishing system must, in the eyes of the Finch committee, continue to provide the vetting and filtering for quality that is the hallmark of the peer review system.
- Cost and sustainability
- It recognises that there are costs in publishing the literature, that the funders of research should take on those costs for the research they fund, and that the mechanisms for doing so must be sustainable.
Based on these principles, the report adduces certain conclusions. The access principle militates for articles being provided openly, so that the pure subscription revenue model, where revenue is based solely on limiting access to those willing and able to pay, is deprecated. The quality principle is taken to argue for journals that themselves provide open access to their articles, rather than relying on authors or institutions to merely provide supplementary access through article repositories. The cost and sustainability principle leads to the idea that funders might pay directly for the costs involved in journals’ processing of articles, these payments substituting for the deprecated subscription revenues. The usability principle entails that when articles are paid for in this way, they ought by rights to be usable as broadly as possible, for instance, through Creative Commons attribution licences.
Now for the bad. The concrete recommendations that the Finch Report outlines do not present a prescription for optimising these principles in the long term. Rather, they pursue short-term prescriptions that will likely provide merely incremental access gains at a very high cost. The primary problem in the Finch Report that leads to this unfortunate consequence is the conflation of two quite different market models as one: full open access and hybrid.
Three market structures
To understand why this is so, we must look to the underlying economics of article publishing, which governs the incentives of the participants in the market. There are three revenue models for journals that are at play in the Finch Report: subscription journals, open-access journals, and hybrid journals.
The subscription journal market
The current predominant market structure of the scholarly journal industry is based on reader-side payments, limiting access to those willing and able to pay subscription fees for the journals. This market structure is manifestly dysfunctional. The reader-side market has led to a well-attested decades-long spiral of hyperinflation of journal prices,2 causing libraries to have to cancel subscriptions, causing publishers to further raise prices to retain revenues. This vicious cycle has two bad effects: the costs to research libraries (and the funding agencies that provide their underwriting through overhead fees) have grown substantially and unsustainably in real terms, while cancellations mean less access to the articles themselves. It is this access problem that the Finch Report strives to address, subject to the cost and sustainability problem as well.
The reasons for the market dysfunction are, by now, well understood. First, the good being sold — access to articles — is a monopolistic good, based on the monopoly right of copyright, and as such is subject to monopoly rents. Second, subscription journals are not (in the economists’ parlance) substitutive goods; access to one journal does not decrease the value of access to another, and in fact may well increase the value (as journals cite each other), making them complementary goods. Complementary goods do not compete against each other like substitutive goods do. Third, journals are sold under conditions of moral hazard; the consumers (readers) are not the purchasers (libraries), and hence are insulated from the costs. As with all moral hazards, this leads to inelasticity of demand and overconsumption. Finally, consolidation of multiple journals under a few large publishers insulates these publishers from economic pressure from cancellations, since they can adjust prices on the remaining journals to compensate for lost revenue.
The subscription market structure thus violates both the access and cost and sustainability desiderata of the Finch Report. Clearly, any long-term strategy for broadening access to articles must move away from this market structure, rather than providing it further support.
In the shorter term, the access problems with the subscription market (though not the sustainability problems) can be greatly alleviated by providing supplementary access to the articles — so-called green open access — by posting copies of article manuscripts in subject-based or institutional repositories. Funding agencies have managed to generate tremendous access gains to their funded research by mandating such supplementary access, beginning with the “public access policy” of the US National Institutes of Health, which requires posting of author manuscripts in NIH’s PubMed Central repository no later than 12 months after publication. Although there is no evidence that immediate green open access has detrimental effect on publisher sustainability or even revenues (Maxwell 2012), embargoes such as those allowed for in the NIH policy (or the more widely used six-month embargoes found in essentially every other funder policy) further reduce any pressure on subscription revenue at the cost of delaying the access. But even if green open access did have an effect on market demand for subscriptions, this would be no argument against mandating it, so long as there were a viable alternative market structure for those journals to use.3
The open-access journal market
And indeed, there is an alternative market structure, one that is in fact highly preferable in that it does not have the same frailties as the reader-side subscription market structure, namely, an author-side market structure. In this system, the good being sold is not access for readers but publishing services for authors — the management of peer review (generating valuable feedback to the author); production services (such as copy-editing, typesetting, graphic design); and most importantly to academic authors, imprimatur of the journal. This market is seen most directly in open-access journals4 that charge a flat article-processing charge (APC), paid by or on behalf of authors. The APC spreads the costs of operating the journal plus a reasonable profit over the articles it publishes.
This market structure doesn’t have the same market dysfunction exhibited by the subscription market, both in theory and in practice. First, publisher services are not a monopolistic good; any publisher can provide them to authors. Second, from the point of view of an article author, journals are substitutive goods, not complementary goods, since submission to one journal does not increase the value of submitting to another journal. In fact, because an article can only be submitted to one journal, journals are perfect substitutes in the author-side market. Third, if authors pay APCs, there is no moral hazard, and if funders or employers pay on their behalf, moral hazard can be mitigated by introducing limits or copayments. (Shieber 2009) Finally, bundling doesn’t apply to the good sold in the open-access journal market as it does in the subscription market.5
For these reasons, one would expect strong market competition and price control in the open-access journal market in theory, and in practice, that is exactly what we see. Not only is there no evidence of hyperinflation, there are signs of strong price competition, with new models arising that can deliver publishing services at a fraction of the cost of subscription journals.
The hybrid journal market
A third market structure, the hybrid journal, plays a frequent role in discussions of open access and in the Finch Report in particular. Hybrid journals are subscription journals that also allow authors to pay an APC to make individual articles available open access. This model has been around for over a decade, and has been taken up by essentially all of the major subscription journal publishers. It has been touted as a transitional mechanism to allow journals to transition from the reader-side payments to writer-side payments. The theory goes that as more and more authors pay the APCs, the subscription fees will be reduced accordingly, so that eventually, once a sufficient fraction of the articles are covered by APCs, the subscription fees can be dropped altogether and the journal converted to full open access. Confusingly, both open-access journals and hybrid journals are sometimes included under the term gold open access, despite the fact that from an economic point of view they are quite distinct.
In particular, the hybrid model is not an appropriate transitional model to true open access. First, hybrid journals have not seen a major uptake in voluntary payment of hybrid APCs in practice. This is not surprising. There’s very little in it for authors, since they typically have a far less expensive alternative method for achieving open-access to their articles through green open access. (In this way, the hybrid model disincentivises publishers from allowing green open access, another perverse effect of the model.) There’s very little in it for universities too, who are unlikely to underwrite these hybrid fees on behalf of authors. Although paying the hybrid fees is supposed to lead to a concomitant reduction in subscription fees, it is extremely difficult to guarantee that this is occurring, and in any case any such reduction is spread among all of the subscribers, so provides little direct benefit to the payer. Of course, payment of hybrid fees could be mandated by a funder. (Getting ahead of ourselves a bit, this is essentially what the Finch Report promotes.) But even if this practice were widespread and most articles had their hybrid fees paid, journals would still have no incentive to switch to the full open-access APC-only model. Why would they voluntarily give up one of their two types of revenue? Finally, hybrid APCs are not subject to the competitive pressures of open-access APCs and would be predicted therefore to be higher. This is exactly what we see in practice, with open-access APCs shaking out in the $750–2000 range and hybrid fees in the $3000–4000 range.
Comparing Recommendations
Put together, these three facts — that the subscription market is inherently dysfunctional, that the open-access market is preferable and sustainable, and that the hybrid model entrenches the former to the exclusion of the latter — it becomes clear what the ideal recommendations should be for funders to provide open access in the short term while promoting a long-term transition to the preferable open-access market structure:
- Require that funded research articles be made openly accessible, either through publication in an open-access or hybrid journal or through green open access supplementary to publication in a subscription journal.6
- Support the open-access journal market by providing underwriting of reasonable APCs, so long as they allow for full reuse rights.
- Do not support entrenchment of the subscription model by underwriting hybrid APCs.
In terms of the four Finch Report desiderata, this approach provides essentially universal open access to UK-funded research (as the NIH policy has in the US for NIH-funded research); preserves quality by allowing authors to publish in subscription, open-access, and hybrid journals alike; works towards broader usability by guaranteeing that APCs provide for full reuse rights; and provides sustainability by supporting a competitive market mechanism and avoiding the high costs and counterproductive nature of paying to entrench the current dysfunctional mechanism. By avoiding payment of hybrid APCs, it forces journals to choose between (i) charging on the reader side and retaining the ability to limit access and (ii) charging on the writer side and allowing full use and reuse rights. Journals would not be able to retain their subscription revenues and pick up additional APCs as well, at least at the public’s expense.
Crucially, these recommendations recognise the difference between the two quite different market structures that are inappropriately lumped together under the rubric ‘gold open access’. Willingness to pay APCs for open-access journals is consonant with the idea that publishers ought to be compensated for their work and recognises that open-access journals cannot be compensated by virtue of their limiting access to those willing and able to pay, nor would we want to do so. Willingness to pay APCs for hybrid journals provides open access to that single article, but disincentivises publishers from moving journals from the subscription market to the open-access market; it is myopic.
By contrast, the pertinent Finch Report recommendations are different.
- Require that funded research articles be made openly accessible through publication in an open-access or hybrid journal.
- Pay for the costs of that open access through underwriting of APCs, whether at open-access journals or hybrid journals.
The change seems small. Instead of underwriting only open-access journals, it underwrites hybrid journals as well. And once both are underwritten, it is not necessary to allow for the admittedly less desirable green open access option.7
Again, we evaluate the recommendations in terms of the four desiderata. By its silence on the matter (outside of mention of “providing access to research data and to grey literature”), the report implies that green open access is to be eschewed even in the short term. However, the requirement to publish in journals providing for payment for open access is likely to lead to broader access, at least for those articles for which funds are available to pay the APCs, and its concentration on publication in open-access or hybrid journals recognises their ability to provide quality control that repositories alone do not. With regard to usability, the report is a bit equivocal in requiring broad licensing in return for APCs, but does say that “support for open access publication should be accompanied by policies to minimise restrictions on the rights of use and re-use, especially for non-commercial purposes”.
The policy fails primarily, however, in the area of cost and sustainability. It provides no mechanism for controlling the dramatic cost increase in covering both subscription fees and high hybrid APCs. (By definition, open-access journals don’t receive both kinds of fees, and their APCs are subject to market competition in a way that hybrid APCs are not, as discussed above.)
Similarly, in the short term, APCs will predominantly be paid to hybrid journals rather than open-access journals, as the hybrids constitute far more of the journal market. Journals will have no incentive to switch to the open-access model, and in fact, will be incentivised not to. Research libraries would still have to maintain their subscriptions in order to cover the substantial body of articles in hybrid journals that are not covered by APCs (because, for instance, they are not UK-funded). The total costs would be greatly increased, while still not solving the underlying market dysfunction.
In fact, the RCUK implementation plans for the Finch Report admit as much. It has become clear that there will be insufficient funds to cover all of the hybrid APCs, so that universities will be taken to be in compliance even if only a fraction of their articles are made available open access by the journals themselves, so long as the remaining fraction are available through green open access. In fact, the RCUK implementation of the Finch Report proposal even allows for longer embargo periods in case the green route is used because of insufficient APC funding (UK 2013). The Finch recommendations thus embed their own negation: they envision having to use green open access to implement a system that denies the utility of green open access.
The alternative, requiring open access ecumenically — through open-access journals, hybrid journals, or green supplementary access — while being willing to underwrite fees for a market structure that work sustainably in the long term — true open access journals — is simultaneously effective in providing access as well as in providing an impetus to a future of the kind of accessible and sustainable journal publishing system that the Finch Report aspires to.
Acknowledgements
Thanks to Peter Suber and Sue Kriegsman for comments on an earlier version of this article.
References
Bosch, Stephen, and Kittie Henderson. 2013. “The Winds of Change: Periodicals Price Survey 2013.” Library Journal (25 April). http://lj.libraryjournal.com/2013/04/publishing/the-winds-of-change-periodicals-price-survey-2013/.
Finch, Janet. 2012. “Accessibility, Sustainability, Excellence: How to Expand Access to Research Publications.” http://www.researchinfonet.org/publish/finch/.
Maxwell, Elliot. 2012. “The Future of Taxpayer-Funded Research: Who Will Control Access to the Results?.” http://www.emaxwell.net/linked/DCCReport_Final_Feb2012.pdf.
Shieber, Stuart M. 2009. “Equity for Open-Access Journal Publishing.” PLoS Biology 7. http://dx.doi.org/10.1371/journal.pbio.1000165.
———. 2013. “Why Open Access Is Better for Scholarly Societies.” The Occasional Pamphlet (29 January). http://blogs.law.harvard.edu/pamphlet/2013/01/29/why-open-access-is-better-for-scholarly-societies/.
Suber, Peter. 2012. “Tectonic Movements toward OA in the UK and Europe.” SPARC Open Access Newsletter (2 September). http://nrs.harvard.edu/urn-3:HUL.InstRepos:9723075.
UK, Research Councils. 2013. “RCUK Policy on Open Access and Supporting Guidance.” http://www.rcuk.ac.uk/documents/documents/RCUKOpenAccessPolicy.pdf.
Notes
- The report also provides a series of recommendations for increasing access within public libraries, strengthening the operations of institutional article repositories, gathering and analyzing pertinent data, reviewing how learned societies might be better supported, adjusting tax policy for journal publishers, and so forth. Many of these recommendations are reasonable and appropriate, but my main concern is the primary recommendations that relate to the market structure of journal publishing.↩
- For instance, Library Journal’s annual Periodicals Price Survey (Bosch and Henderson 2013) reported a 6% average price increase for 2013 during a period in which inflation increased at 1.7%, continuing their tracking of a multiple-decades-long trend of serials price increases at several times the rate of inflation.↩
- See the discussion by Peter Suber arguing that we should “weigh the demonstrable degree of harm to publishers against the demonstrable degree of benefit to research, researchers, research institutions, and taxpayers…. In short, we needn’t let fear of harm serve as evidence of harm, and we needn’t assume without discussion that even evidence of harm to subscription publishers would justify compromising the public interest in public access to publicly-funded research.” (Suber 2012)↩
- The term ‘open-access journal’ covers any journal that makes its scholarly article content freely and openly available online. However, we use the term here (as in the Finch Report) to refer to journals using a revenue model based on APCs. Although at present only a minority of OA journals charge any APCs, for the purpose of discussion of revenue models, the APC approach is the most plausible one for sustaining open-access journals in the long run. Already, it is used nearly universally by the major open-access journal providers.↩
- I have previously provided a fuller discussion of these issues of the difference between the subscription market and the open-access market, especially in the context of scholarly society publishing programs. (Shieber 2013)↩
- The treatment of hybrid journals we propose is appropriately subtle. Though authors are free to provide for the required open access by publishing in a hybrid journal (1), the funders would not underwrite the associated fee (3) as they would for a fully open-access journal (2).↩
- Although there are subscription journals that are not hybrid journals, the major publishers are uniformly moving in the direction of providing for hybrid fees, and smaller publishers are likely to follow suit over time. The Finch Report is silent on what to do about articles published in non-hybrid subscription journals. In the RCUK implementation documents, they allow green open access just in that case.↩
Policies, publishers, and plagiarism prosecution
May 15th, 2013
 |
| …going after plagiarists on legal grounds… “Judge Coco Declares Ang Out of Line!” image by flickr user Coco Mault used by permission. |
One of the services that journal publishers claim to provide on behalf of authors is legal support in the case that their work has been plagiarized, and they sometimes cite this as one of the reasons that they require a transfer of rights for publication of articles.
Here’s a recent example of the claim, forwarded to me by a Harvard author of a paper accepted for publication in a Wiley journal.[1] The article falls under Harvard’s FAS open-access policy, by virtue of which the university held a nonexclusive license in the article. The author chose to inform the journal of this license by attaching the Harvard addendum to Wiley’s publication agreement. Wiley’s emailed response to her included this explanation:
You recently had a paper accepted for publication in [journal name] and signed an exclusive license form to which you attached an addendum from Harvard University. Unfortunately, we are unable to accept this addendum, as it conflicts with the rights of the copyright holder (in this case, the [society on whose behalf Wiley publishes the journal]). They guarantee the same rights that our copyright forms guarantee, but Harvard University, unlike Wiley, offers no support if your article is plagiarized or otherwise reused illegally.
(It then went on to list various rights that Wiley grants back to authors of articles in this journal, such as posting manuscripts in repositories, all of which are laudable, though they remained silent on their required 12-month distribution embargo.)
I have no problem with publishers requiring waivers of the Harvard open-access policy as a condition of publishing in their journals. They are their journals after all. And in the event, only a small proportion of articles, in the low single digits, end up needing waivers. But I bristle at the transparently disingenuous argumentation for their requirement. They make two separate arguments.
-
The addendum “conflicts with the rights of the copyright holder”, the society on whose behalf Wiley publishes the journal.
Wait, what? How is the society the copyright holder? Until the author signs a publication agreement, the author is the copyright holder. And the publication agreement itself doesn’t involve a transfer of copyright, but rather, an exclusive license to Wiley on behalf of the society. And anyway, whether it’s an exclusive license or a wholesale transfer of copyright, that doesn’t conflict with the addendum by virtue of the plain words in the addendum: “Notwithstanding any terms in the Publication Agreement to the contrary, Author and Publisher agree as follows:…”.
-
If the addendum were allowed, “Harvard University, unlike Wiley, offers no support if your article is plagiarized or otherwise reused illegally.”
Suppose that were true. (Though how would Wiley know what support Harvard gives its faculty when their work is plagiarized or used illegally?) Why would that be an issue? Nothing stops Wiley from providing that support on behalf of its authors, with or without the addendum. Either way it still receives an exclusive license from the author. Others illegally using the work are still violating that exclusive license.
Unless of course the violator received a license by virtue of the prior nonexclusive license to the University mentioned in the addendum. Could that happen? Nope. The university uses its license only to authorize a particular set of uses. You can read them at the DASH Terms of Use page (see the “Open Access Policy Articles” section). They do not include plagiarism as a permitted use, or any illegal uses. (Is it even necessary to point that out?) The university also grants the authors themselves the ability to exercise rights in their article. But if someone explicitly received and exercised rights from a rights-holding author, it’s hard to see how that’s an illegal use.
More fundamentally, however, there’s a basic premise that underlies this talk of publishers requiring exclusive rights in order to weed out and prosecute plagiarism, namely, that publishers would not be able to do so if they didn’t acquire exhaustive exclusive rights. But there’s no legal basis to such a premise that I can imagine.
Plagiarism per se is not a rights matter at all, but a violation of the professional conduct expected of scholars. Pursuing plagiarists is a matter of calling their behavior out for what it is, with the concomitant professional opprobrium and dishonor that such behavior deserves. Publishers should feel free to help with that social process; they don’t need any rights to do so.
Being “otherwise used illegally” gets more to the heart of the matter, as rights violations are presumably what the publisher has in mind. But it’s hard to see how publishers would need any rights themselves just to help an author out in prosecuting a rights violation. Suppose a publisher, rather than acquiring exclusive rights in an article, instead had authors license their articles under a CC-BY license. The publisher could still weed out and prosecute illegal uses of the article. There would be fewer opportunities for illegal use, since CC-BY allows lots of salutary kinds of use and reuse, subject only to proper attribution to the author and journal. But illegal uses might still arise from violating the attribution requirement of the CC-BY declaration. Nothing stops the publisher from looking for such gross plagiarisms of the articles they publish that rise to the level of rights violation, and from prosecuting the plagiarists on behalf of the authors. They could even write that into their agreements: “The Author grants the Publisher permission to prosecute violations of this license on the Author’s behalf, etc.”[2]
(As an aside, the offer to prosecute plagiarists and rights violators isn’t much of a benefit in practice. How many instances of publishers going after plagiarists on legal grounds based on the publisher’s holding of rights have there ever been? As Jake said, “Isn’t it pretty to think so?”)
What’s really going on here is not a mystery. The publisher doesn’t like the idea of the author distributing copies of her work. The primary difference between the rights the publisher wants to grant the author and the rights specified in the open-access policy is that the former stipulates that the author not distribute copies of her article for twelve months after publication. The publisher is objecting so as to force a waiver of the open-access policy license to preserve their ability to limit access to the article. Of course, saying “we won’t accept the addendum because we want to limit people reading your article” doesn’t sound nearly as good as “otherwise we couldn’t go after plagiarists”.
Publishers are welcome to require waivers of Harvard’s open-access policies and the similar policies at other institutions, but hiding behind faux arguments in their explanations to authors isn’t attractive. They should come clean on the reasoning: They think it harms their business model.
-
There’s a long history of this kind of thing. For instance, Peter Suber addressed the issue as raised by the International Association of Scientific, Technical and Medical Publishers way back in 2007. ↩
-
Not to mention the fact that open accessability of articles makes plagiarism easier to detect, and therefore provides a disincentive to plagiarize in the first place. For example, researcher at arXiv have reported on experiments for automatically finding cases of plagiarism in its open-access collection. Services like the Open Access Plagiarism Search project sponsored by the German Research Foundation (DFG) are working to make good on this potential. ↩
Open letter on the White House public access directive
February 28th, 2013
 |
| …White House… “White House” image by flickr user Trevor McGoldrick. |
As has been widely reported, this past Friday the White House directed essentially all federal funding agencies to develop open access policies over the next few months. I wrote the letter below to be forwarded to faculty at the Harvard schools with open-access policies, to inform them of this important new directive and its relation to the existing Harvard policies.
Why open access is better for scholarly societies
January 29th, 2013
[This is a heavily edited transcript of a talk that I gave on January 3, 2013, at a panel on open access at the 87th Annual Meeting of the Linguistic Society of America (LSA, the main scholarly society for linguistics, and publisher of the journal Language), co-sponsored by the Modern Language Association (MLA).]
Thank you for this opportunity to join the others on this panel in talking about open access. I will concentrate in particular on the relationship between open access and the future of scholarly societies. I’m thinking in particular of small to medium scholarly societies, which have small publishing programs that are often central to the solvency of the societies and to their ability to do the important work that they do. In one sense it should be obvious, and I think it’s been made obvious by the previous speakers, that open access meshes well with the missions of scholarly societies. LSA’s mission, for instance, is “to advance the scientific study of language. LSA plays a critical role in supporting and disseminating linguistic scholarship both to professional linguists and to the general public.” [Emphasis added.] So I’ll just assume the societal benefit of open access to researchers and to the general public alike. For the purpose of conversation let’s just take that as given.
Nonetheless, many scholarly societies, and the faculty that support them, are worried that open access – at least as they understand the concept – could exacerbate the serious financial distress that many of those societies are already under, and even undermine their very existence and thereby their ability to carry out this mission. I’ve heard faculty worry that even “green” open access (self-archiving of articles in open-access repositories) could undermine the economics of journal publishing in such a way that their scholarly societies could be endangered.
I want to argue that there is a real threat that many scholarly societies accurately perceive in their publishing programs, but that we must be careful not to misdiagnose this problem. In fact, a general move to open access would be the best outcome for scholarly society publishers. If the entirety of journal publishing magically metamorphosed somehow to an open-access system, scholarly society publishers would be much better off. From a strategic point of view then, the best course of action for scholarly societies and for the faculty and researchers who support them would be to promote a shift to open access as widely and as quickly as possible. Now, the threat that societies perceive is an economic threat, so my remarks will be almost entirely economic in nature; I’m just warning you. My talk certainly will have no linguistic import at all.
Economic properties of the subscription market
Let me turn first to some basic truths about the subscription journal market that I’ve come to realize are important in understanding what the underlying economic issues are.
Journal access is a complementary good
The first is that different journals — viewed as products, as goods being sold — are in economists’ terms complements, not substitutes. Substitute goods are products like Coke and Pepsi. If you have one it decreases the value of the other to you, as they fulfill similar functions. Complements are products like a left shoe and a right shoe – that’s the most extreme case. If you have one it increases the value to you of the other. There are less extreme cases of economic complements – printers and toner cartridges, peanut butter and jelly, pencils and erasers.
What about scholarly journals? Suppose you’re a patron of a library that subscribes to a bundle of, let’s say, Elsevier journals, including the journal Lingua. Does the library subscription to that journal make you more or less interested in reading, say, Language? (We’re holding cost aside. When thinking about complements or substitutes, it’s just about the value to the consumer, not the cost.) Of course, you’re not less inclined to read Language just because the library subscribes to Lingua. In fact you may be more inclined, because some Lingua articles will cite Language articles. You read the Lingua article, you want to to read the Language article it cites. So that would lead you to track down those articles and read them if the library had a subscription. And vice versa: a subscription to Language can increase the value of a subscription to Lingua. So journals are economic complements, not substitutes.
Inefficiency in the subscription market
This has important ramifications. Non-substitutive goods don’t compete against each other and complementary goods in fact support each other in the market. If consumers suddenly buy a lot more Coke, Pepsi is worried. But if peanut butter sales skyrocket, the jelly manufacturers are elated. So the complementary subscription of individual journals means that there’s limited market competition between journals, and limited competition leads to inefficiency in the journal market. (That’s not to say that there isn’t competition between publishers. But as we’ll see, the primary form of that competition is in competing to acquire journals.)
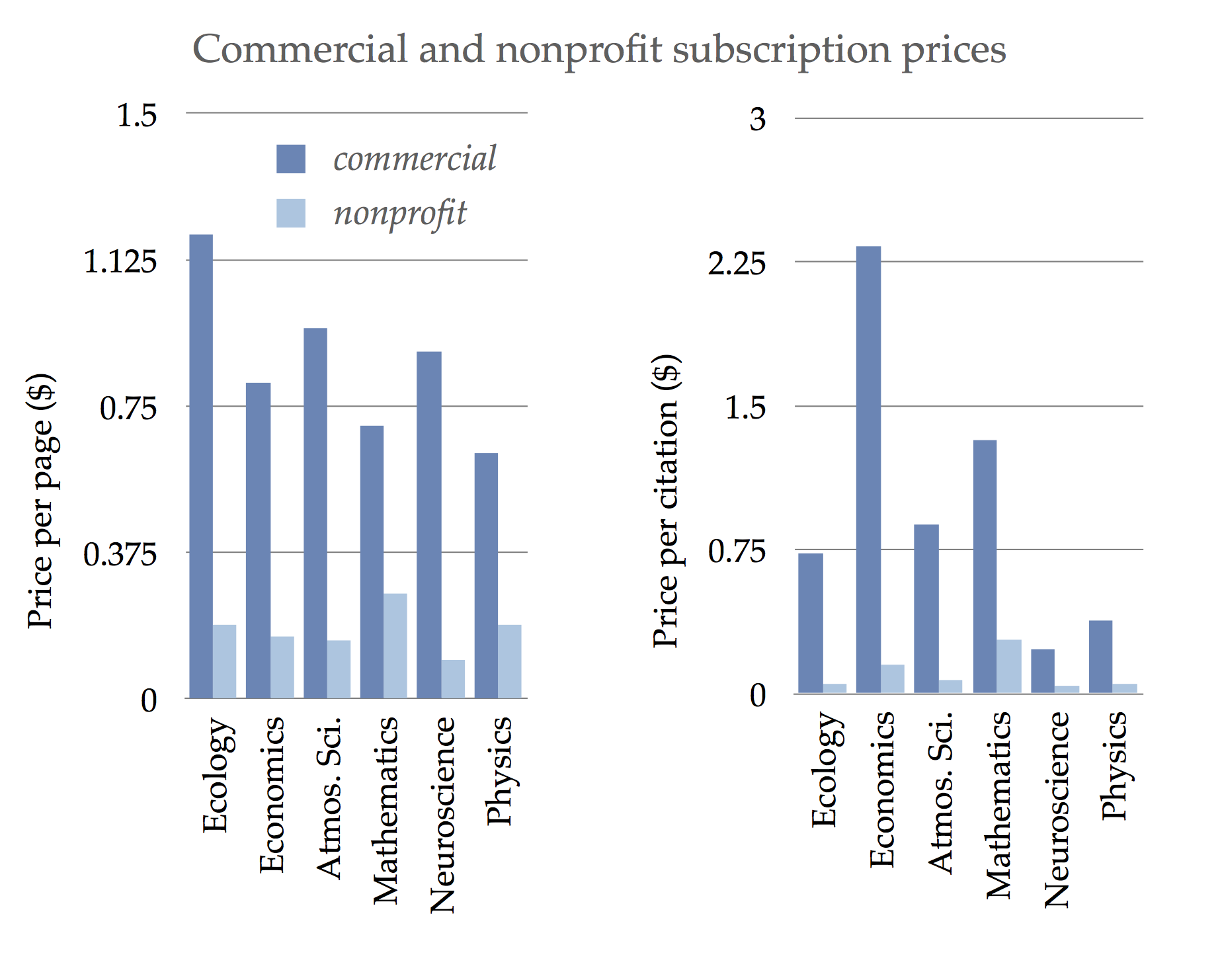 |
| Figure 1: Average journal prices in a range of fields, differentiated by commercial and non-profit publishers. Left is based on prices as dollars per page. Right is based on dollars per citation, to normalize for quality. Data are from Bergstrom and Bergstrom, Journal pricing across disciplines, 2002. |
We can see ample evidence of this kind of inefficiency. One clear form of evidence for inefficiency is wide price disparities. The graph in Figure 1 shows average journal prices in a whole range of fields. The data is from a study by Bergstrom and Bergstrom, and they differentiated the cost of the journals by whether the publisher is commercial or non-profit. The dark blue represents the commercial publishers, the light blue the nonprofit publishers. Notice that the commercial publishers on average charge about five times more for their journals than non-profit publishers, as measured by price per page. Now you might think there is a good explanation for this disparity: perhaps these aren’t comparable products. Perhaps the commercial publishers are selling a much better product, higher quality journals, and it’s therefore more expensive to develop them, and that’s what accounts for the price differential. So we can normalize for that by using a proxy for quality. One widely used proxy for quality, admittedly not a great one but at least widely touted by journals themselves through the ubiquitous “Impact Factor”, is the number of citations the journal receives. The second graph in Figure 1 thus shows price per citation. Measured this way, commercial journals are fifteen times more expensive than non-profit journals from the same field. Now, linguistics was not one of the fields examined in this study. But the same holds true here as well. For example, the subscription rate for LSA’s journal Language, published by a non-profit of course, is $3.31 per citation, whereas Elsevier’s Lingua is $32.30 per citation – almost exactly ten times more expensive.
This kind of price differential is a clear sign of market failure, especially as it has been sustained over decades. You just do not get this kind of price disparity preserved over long periods of time in well functioning markets. Go to the various grocery stores in your neighborhood and see if you can find apples at different grocery stores at a price differential of a factor of ten. It does not happen. Such price disparities are a clear sign of inefficiency.
Journal access is a monopolistic good
 |
| Figure 2: Elsevier revenues, profit, and profit margin, 2002–2011. Data are from Mike Taylor, The obscene profits of commercial scholarly publishers, 2012. |
The second basic truth is that the good being sold in the subscription market is access, and access is a monopolistic good. The monopoly is enabled by copyright, founded in the government’s ability as codified in Article I Section 8 of the Constitution to provide an exclusive right to the creator of a work for a limited period of time. Subscription publishers acquire exclusive rights to the articles they publish — typically by acquiring copyright, sometimes by acquiring an exclusive license, which is a distinction without a difference — and this allows publishers in theory and in many cases in practice to extract monopoly rents in selling access to the articles. We see evidence of this as well. For example, in Figure 2, I show a graph of the revenues, profits, and most importantly the profit margin, for the publisher Elsevier over the last decade. It’s quite a good business with annual revenues of over $2 billion, but that’s not the big point. The big point is the extraordinary 35–40% profit margins. It’s not just Elsevier. Many large commercial publishers have maintained these kinds of profit margins over a long period of time. An interesting thing to look at is the steady increase in the margins even during the financial crisis starting in 2009 when, for instance, many university endowments and library budgets dropped precipitously. Harvard’s endowment went down by 30% but Elsevier did just fine, and the other large publishers as well. So maintaining those kinds of profit margins again is a sign of the ability to extract monopoly rents.
Journal access is a bundled good
The third basic truth is that pricing is controlled not at the level of the individual journal but at the level of a bundle of journals. The large publishers have portfolios of hundreds to thousands of journals. They can therefore apply prices to a bundle of journals, not a single journal. They can show vastly different prices to different buyers and use the bundles to incentivize buyers, the libraries, to pay larger fees. The upshot of this point, that pricing happens at the bundle level and not the journal level, is that a library can find it extremely difficult to control its expenditures by canceling individual journals because the publisher can just price the smaller bundle at essentially the same cost as the larger bundle.
I’ll tell you a personal story. Some years ago, Harvard was one of the first universities to cancel the “big deal” with Elsevier. I don’t want to pick on Elsevier. They’re not bad people. They’re a wonderful group of folks. Lots of the large publishers of journals work this way and it’s not because they’re evil or anything like that. I just mention the Elsevier case as a convenient story. Harvard was one of the first universities to cancel its “big deal” and went a la carte on the journals. In the School of Engineering and Applied Sciences, my own school, we had been subscribing to around 130 Elsevier journals in engineering and applied sciences as I recall. We took the opportunity to cancel about 100 of these journals, leaving something like 30 journals, hoping to recoup some costs. And we did. The first year we recouped about 20%. The following year the total cost was back where it had been before the cancellations, and it has increased steadily from there. From the library’s point of view, you can’t win by canceling journals, because the product is not the journal, it’s the bundle.
Edlin and Rubinfeld, in a Law Review article about possible anti-trust implications of this bundling, say “The immediate effect of [bundled pricing] has been to move competition from individual journals to large bundles of journals. … Creating a large bundle of journals to compete with Elsevier or Kluwer seems almost insurmountable. … There are indications that [bundled pricing] is hindering entry. Librarians … say that they would spend more money for journals from smaller and alternative publishers if they could achieve proportionate savings from reductions. By selling electronic bundles, publishers have erected a strategic barrier to entry at just the time that the electronic publishing possibility has made it increasingly possible for alternative publishers to overcome the existing structural barriers.” The fact that competition is at the level of bundles, not at the level of journals, is very important.
The result: market dysfunction
 |
| Figure 3: Scholarly journal expenditures percentage increase 1986–2010 compared to consumer price index. Data from Association for Research Libraries. |
When we put all these properties of the journal market together, the end result is market dysfunction and a steady long-term hyperinflation in journal expenditures by libraries. Figure 3 shows a graph of serials expenditures over the last couple of decades, the dark blue line. The light blue line is the consumer price index, a proxy for the ambient rate of inflation. You can see that serials expenditures in research libraries have been going up at something like three times the rate of inflation for decades. Exponential real growth in the cost of journals is an unsustainable state of affairs.
I return to the issue of inefficiency. Why is it that the non-profit publishers are so much more efficient than the commercial publishers? Not in every case of course but on average the difference is really striking. There are a couple of possible reasons. One is that the non-profits tend to be scholarly societies who may be motivated not by profit maximization but by service to the field. I think that’s true to a certain extent. But also the non-profits tend to be small publishers with few journals – maybe one, two, three, five, ten journals. Since bundle size governs market power, non-profits have less ability to grow margins. And scholarly societies rightly complain that they’re being squeezed. From the point of view of libraries, if you have to cancel something you can recoup revenue if you cancel the journals from a small publisher. You can’t recoup revenue if you cancel journals from the large commercial publishers. As a library, what are you going to do? Cancel scholarly society journals, just as the societies have been rightly complaining about.
But notice that the problem that scholarly societies face, a problem that will only increase in a status quo future, is based not on open access but on inherent properties of the subscription market that they participate in. For scholarly societies, the status quo is not a good alternative. Doing nothing is a failing strategy.
Open-access journals as a preferable system
The idea of open-access journals is that they provide access to the articles for free. How can this be a better system for scholarly societies, given that much of the societies’ revenues may come from the publishing program?
Open-access journals don’t charge for access, but that doesn’t mean they eschew revenue entirely. Open-access journals are just selling a different good, and therefore participating in a different market. Instead of selling access to readers (or the readers’ proxy, the libraries), they sell publisher services to the authors (or to the authors’ proxy, their research funders).
In fact there are now over 8,500 open-access journals listed in the Directory of Open Access Journals. Some of them have been mentioned already on this panel: Linguistic Discovery, Semantics and Pragmatics. The majority of existing open-access journals, like those journals, don’t charge author-side article-processing charges (APCs). But in the end APCs seems to me the most reasonable, reliable, scalable, and efficient revenue mechanism for open-access journals. This move from reader-side subscription fees to author-side APCs has dramatic ramifications for the structure of the market that the publisher participates in.
Economic properties of the open-access journal market
The open-access APC market has quite different properties from the subscription market. Recall the basic truths about the subscription market. Journals are complements, not substitutes. There’s limited market competition. The product being sold is a monopolistic good. Pricing is controlled at the bundle level. What are the corresponding properties of the publisher services market, the market that open-access journals participate in? In that market, the purchaser of the good is the author or the author’s proxy, not the reader or reader’s proxy. And from the point of view of an author, two journals are not complements but substitutes. You can publish your article in the Journal of Linguistics or Lingua or better yet in Language. But having published it in one, you have no incentive to publish it in the other. In fact, you’re not allowed to publish in both, making journals perfect substitutes. There is no value to the second journal once you’ve published the article in the first journal, from the point of view of the author trying to get a publication.
So journals compete for authors in a way they don’t for readers, and this competition leads to much greater efficiency. Open-access publishers are highly motivated to provide better services at lower price to compete for authors’ article submissions. We actually see evidence of this competition on both price and quality happening in the market. I won’t go through examples but have written about it previously.
Second, publisher services on the author side are not a monopolistic good. Anyone can provide those services. In fact because the service is a knowledge good, there are exceptionally low barriers to entry. Kai von Fintel and David Beaver can just unilaterally set up Semantics and Pragmatics; maybe they’ll be successful and maybe they won’t. In this case, it turned out pretty well. The low barrier to entry further enhances competition and improves the efficiency of the market.
Finally, pricing is controlled not at the level of the bundle of journals. You don’t care about the bundle of the publisher when you’re an author submitting to a journal. You care about the journal. Actually, pricing is not even at the journal level, but at the level of the individual article. So price competition happens at that level as well, with journals competing for individual articles on price as well as quality.
In summary, the open-access APC market is a more efficient market than the closed-access subscription market for reasons of basic economics. That’s not just my opinion. Claudio Aspesi, senior analyst at Sanford Bernstein studying the finances of publishing companies, has estimated that a transition to open access would lead to Elsevier cutting its margins by 41–89%.
Comparative cost of open-access journals
Let me say something about the overall cost for the two kinds of models. The APCs that open-access journals charge range from $0 to around $3,000. The median turns out to be zero. But for those open-access journals that do charge a fee, the mean is around $1,200, and reasonable sustainable fees seem to be shaking out in the $1,000 to $1,500 range. Let’s call it $1,500. Since article processing fees are essentially the totality of revenue that open-access journals receive, the APC is a reasonable figure for average revenue per article. There are open-access publishers who are profitable in that range, including commercial open-access journals.
What’s the corresponding number for subscription journals? What is their average revenue per article? The Scholarly Publishing Roundtable reported total 2008 revenue for scholarly publishing at $8 billion on 1.5 million articles, the vast bulk of that revenue coming from subscription fees. Average revenue per article for subscription journals is, by that measure, over $5,000 an article. Remember that this averages over all of the journals — the high quality and the low alike.
So what’s happening is that authors one way or another are paying. Either you’re paying an APC to an open-access journal or you’re paying with your copyright to a subscription journal, which the publisher then monetizes, turning it into about $5,000 per article. It turns out that if we moved from a subscription journal world to an open-access world, the institutions of the world would go from paying, on average, $5,000 an article to about $1,500. Let’s suppose the $1,500 estimate is unreasonably low. Let’s suppose that really the average APC would be what the most high-end open-access journal, PLoS Biology, now charges – that’s $2,900; call it $3,000. If every article moved from the subscription model to an open-access APC model at the high end of cost – we would still be saving 40%. And more importantly, we would be better executing the scholarly society mission by providing the broadest possible dissemination.
Scholarly societies as open-access publishers
Who wins in this kind of market – a non-monopolistic, competitive market of substitutes where the processing fees are considerably less than the current cost per article for subscription journals? The publisher who wins in that market is the publisher who can provide the best services, including imprimatur, at the lowest price to the author, that is, the publisher who is most efficient. Scholarly society publishers would have a huge lead in this market, because they are manifestly more efficient than commercial publishers by a large factor. If the scholarly journal market were structured as the open-access journal market rather than the subscription journal market, scholarly society publishers would be the big winners. And scholarly societies are beginning to realize that open access could be a boon not only to their mission – that much should be uncontroversial – but also to their solvency. Perhaps for this reason, some 600 scholarly societies, including the LSA, are already publishing open-access journals.
At the root, the reason that scholarly societies benefit from playing in the open-access APC market rather than the closed-access subscription fee market is the difference in the goods being sold. When the good is a journal bundle, the companies with the biggest bundles, the large commercial publishers, win. When the good is publisher services for an individual article, the publishers that can deliver those services for an individual article most efficiently, the non-profit publishers, win. Sure, there are economies of scale, but empirical evidence shows that the scholarly societies are already far better able to efficiently deliver services despite any scale disadvantage.
The problem for open access: the transition
Now, all that sounds great, but I don’t want to be too positive. As I said at the outset, there is a real worry that society publishers should have about the open-access APC market. But it’s not that they’d be at a competitive disadvantage in that market; I think that they’d have a huge advantage. And it’s important to remember that they’re already at a huge disadvantage in the subscription journal market; status quo is a failing strategy. Rather the problem is this. Open-access journals are at a disadvantage in their competition for authors against subscription journals. That is, the problem arises across the two markets. When the only kind of journals are open-access journals, scholarly societies have the upper hand. When there are both kinds of journals in the market, both subscription journals and open-access journals, the open-access journals are at a competitive disadvantage because (from the author’s point of view) publishing is free in a subscription journal. (Of course, it’s not really free; it’s just that the research libraries of the world are underwriting the very high $5,000 cost per article.) By contrast, in an open-access APC journal, the author personally could be out let’s say $1,200 or $1,500 or whatever. This is a problem not just for scholarly societies but for all publishers exploring the possibility of going fee-based open access.
To make a transition possible, what we, as supporters of scholarly societies, should be working on is placing open-access journals on a level playing field with subscription journals. There’s a principle at stake here, and the principle is this: Dissemination of research results is an inherent part of the research process. This is something that publishers themselves are frequently pointing out — that they are part of the research process. Consequently, the funders of that research should underwrite dissemination of the results. Who are the funders of the research? In science, technology, and medicine, public and private funding agencies are the primary research funders. By this principle then, the funding agencies giving the grants in those areas would be on the hook to pay the $1,000 or $1,200 or $1,500 or $2,900 publication fees. Most funding agencies already will pay for publication costs for open-access journals (though not in an ideal way, which I’ve written about in the past). What about fields where there aren’t funding agencies handing out large grants? In the humanities and social sciences, universities are the de facto primary research funders. Faculty members in universities are doing research in those fields as part of their employment as researchers. As the primary research funders in the humanities and social sciences, in linguistics in particular, the universities that employ us should be on the hook to disseminate the research results that their researchers generate.
This is the principle behind an effort called the Compact for Open-Access Publishing Equity. It was set up by a group of five universities initially — Cornell, Dartmouth, Harvard, MIT, and Berkeley — to place the open-access revenue model on a more level playing field with the subscription model. Since then another dozen or so institutions have signed on. The Compact says that these universities commit to providing a mechanism for underwriting reasonable publication fees for articles written by their faculty and published in fee-based open-access journals. From the point of view of these signatory institutions, and the many other institutions that don’t happen to be signatories but have similar funding policies, if you structure your journal as an open-access journal charging a publication fee, you don’t need to worry that the authors will be personally out of pocket to pay those fees; the university will pay on their behalf.
Next steps
Given that the open-access publication fee market would be preferable from the point of view of scholarly societies and their members, what should scholarly societies be doing from the strategic point of view? What is in the best interest of us as supporters of scholarly societies? Happily the best interest of scholarly society publishers is the best interest of the scholars themselves, namely as rapid a transition to open access as possible. So scholarly societies should be doing what they can to speed that transition, and I’m glad to say that the LSA and the MLA are working in that direction. I wish all scholarly societies would do so as well.
Of course, the ideal action for a scholarly society is to convert all of its journals to open access. By doing so, they help set expectations among authors that we don’t restrict access to articles, thereby hastening the day that closed-access journals find it impossible to compete for authors.
But some scholarly societies may still find it too worrisome to take such a bold move, not because they disagree with my conclusion that they fare better in an open access world, but because they fear not making it through the transition to that world. I’m sympathetic to that worry. Still, there are important actions that societies can take short of converting all of their journals to open access, actions that will still greatly contribute to changing the expectations of scholars that research results should be and are being made accessible. Scholarly societies can:
- Experiment with open access for at least some of their journals (as LSA is doing with Semantics and Pragmatics), thereby gaining exactly the experience with open-access publishing that will be invaluable in the future.
- Along the same lines, commit to open access for any new journals.
- For the legacy non-open-access journals, provide delayed open-access to articles, making them available with a broad license after, say, six months or one year. The LSA has already taken this important step. Once conditions are right, the delay can simply be dropped.
- Explicitly allow self-archiving of articles published in their journals, the green open access that I alluded to at the start of the talk. Doing so sends a strong signal that the society supports open access. At the same time, there is “no persuasive evidence that increased access threatens the sustainability of traditional subscription-supported journals, or their ability to fund rigorous peer review.” TheLSA does this, and the MLA recently announced that they are modifying their publication agreement along these lines, and even allowing distribution of the final published version after one year.
- Recognize, accommodate, and promote university and funder open-access policies. Accommodation requires only the addition of a single sentence to a publisher’s publication agreement. The pertinent sentence taken from the Science Commons addenda is this:
Where applicable, Publisher acknowledges that Author’s assignment of copyright or Author’s grant of exclusive rights in the Publication Agreement is subject to Author’s prior grant of a non-exclusive copyright license to Author’s employing institution and/or to a funding entity that financially supported the research reflected in the Article as part of an agreement between Author or Author’s employing institution and such funding entity, such as an agency of the United States government.
(My guess is that it should be possible to generate an English version of such a sentence as well.)
- Support pro-open-access legislation such as the Federal Research Public Access Act. At the least, scholarly societies should disavow anti-open-access statements made on their behalf by publishing consortia, as the MLA did in its statement opposing the Research Works Act.
- Leverage the society’s membership to push for open-access underwriting by funding agencies and by universities such as envisioned by the Compact for Open-Access Publishing Equity.
To the extent that we can get a transition to a primarily open-access publishing system to happen, scholarly societies, their members, and the general public will all be much better off, which is a happy confluence of interest. Thank you very much.
Aaron Swartz’s legacy
January 13th, 2013
Government zealotry in prosecuting brilliant people is a repeating theme. It gave rise to one of the great intellectual tragedies of the 20th century, the death of Alan Turing after his appalling treatment by the British government. Sadly, we have just been presented with another case. Aaron Swartz committed suicide at his apartment in New York this week in the face of an overreaching prosecution of his JSTOR download action. I never met him, but I understand from those who knew him well that he was a brilliant, committed person who only acted intending to do good in the world. I’m on the record disagreeing with the particulars of the open access tactic for which he was being prosecuted, on the basis that it was counterproductive. But I empathize with the gut instinct that led to his effort. I hope that it will inspire us all to redouble our efforts to eliminate the needless restraints on the distribution and use of scholarship as Swartz himself was trying to achieve.
How not to entice an author
November 6th, 2012
 |
| …There’s a “tree” in it… “Fall New England” image by flickr user BrtinBoston. Used by permission. |
I received the attached email, inviting a contribution to a journal called Advances in Forestry Letter. Yes, that’s “Letter” in the singular, which is even still optimistic given the number of papers they’ve published so far, viz., none. For a week or so after I received the email, the journal’s web site was down. It’s back up now, and we can glean some further information about this “journal”. It is claimed to be published by “World Academic Publishers” (already listed in Jeffrey Beall’s list of predatory publishers), though the publisher’s site does not list the journal as of this writing. The listing of covered topics from their “Focus and Scope” page seems to have been plagiarized from the corresponding listing for the MDPI journal Forests.
Why am I, a computer scientist, being invited to submit an article on forestry? On the basis of being the author of an article entitled “Optimal k-arization of synchronous tree-adjoining grammar“. (Actually, they got that wrong too. I’m a co-author, along with Rebecca Nesson and Giorgio Satta.) See? There’s a “tree” in it. It must be about forestry.
I have half a mind to submit the article to them (after making it “80% different”) and see what happens. Read the rest of this entry »
Guide released on good practices for university open-access policies
October 17th, 2012
I’m pleased to forward on the announcement that the Harvard Open Access Project has just released an initial version of a guide on “good practices for university open-access policies”. It was put together by Peter Suber and myself with help from many, including Ellen Finnie Duranceau, Ada Emmett, Heather Joseph, Iryna Kuchma, and Alma Swan. It has already received endorsements from the Coalition of Open Access Policy Institutions (COAPI), Confederation of Open Access Repositories (COAR), Electronic Information for Libraries (EIFL), Enabling Open Scholarship (EOS), Harvard Open Access Project (HOAP), Open Access Scholarly Information Sourcebook (OASIS), Scholarly Publishing and Academic Resources Coalition (SPARC), and SPARC Europe.
The official announcement is provided below, replicated from the Berkman Center announcement. Read the rest of this entry »
Open Access Week 2012 at Harvard
October 8th, 2012
 |
| …set the default… |
Here’s what’s on deck at Harvard for Open Access Week 2012 (reproduced from the OSC announcement).
From October 22 through October 28, Harvard University is joining hundreds of other institutions of higher learning to celebrate Open Access Week, a global event for the promotion of free, immediate online access to scholarly research.
Harvard will participate in OA Week locally by offering two public events that engage this year’s theme, “Set the default to open access.”
On October 23rd at 12:30 p.m., the Berkman Center for Internet & Society and the Office for Scholarly Communication will host a forum entitled “How to Make Your Research Open Access (Whether You’re at Harvard or Not).” OA advocates Peter Suber and Stuart Shieber will headline the session, answering questions on any aspect of open access and recommending concrete steps for making your work open access. The event will be held at the Berkman Center, 23 Everett Street, 2nd Floor. The Berkman Center will also stream the discussion live online. See the Berkman Center website for more information and to RSVP.
On October 24, a panel of experts will consider efforts by the National Institutes of Health to ensure public access to the published results of federally funded research. “Open Access to Health Research: Future Directions for the NIH Public Access Policy” will feature a discussion of the challenges and opportunities for increasing compliance with the NIH policy. The event, co-sponsored by the Office for Scholarly Communication, Right to Research Coalition, and Universities Allied for Essential Medicines, will be held at the Harvard Law School in Hauser Hall, room 104. More information is available at the Petrie-Flom Center website.