
Sydney —  Australia’s privacy principles are among the few in the world that require organizations to give individuals personal information gathered about them.* This opens the path to proving that we can do more with our own data than anybody else can.
Australia’s privacy principles are among the few in the world that require organizations to give individuals personal information gathered about them.* This opens the path to proving that we can do more with our own data than anybody else can.
Estimating the size of the personal data management business is like figuring the size of the market for talking or driving. (Note: we can also do more with those than companies can.)
Starting us down this path is Ben Grubb (@BenGrubb) of the Sydney Morning Herald. Ben requested personal data held by the Australian telco giant Telstra, and found himself in a big fight, which he won. (Here’s the decision. Telstra is appealing, but they’re still gonna lose.)
Bravo to Ben — not just for whupping a giant, but for showing a path forward for individual empowerment in the marketplace. Thanks to Australia’s privacy principles, and Ben’s illustrative case, the yellow brick road to the VRM future is widest in Oz.
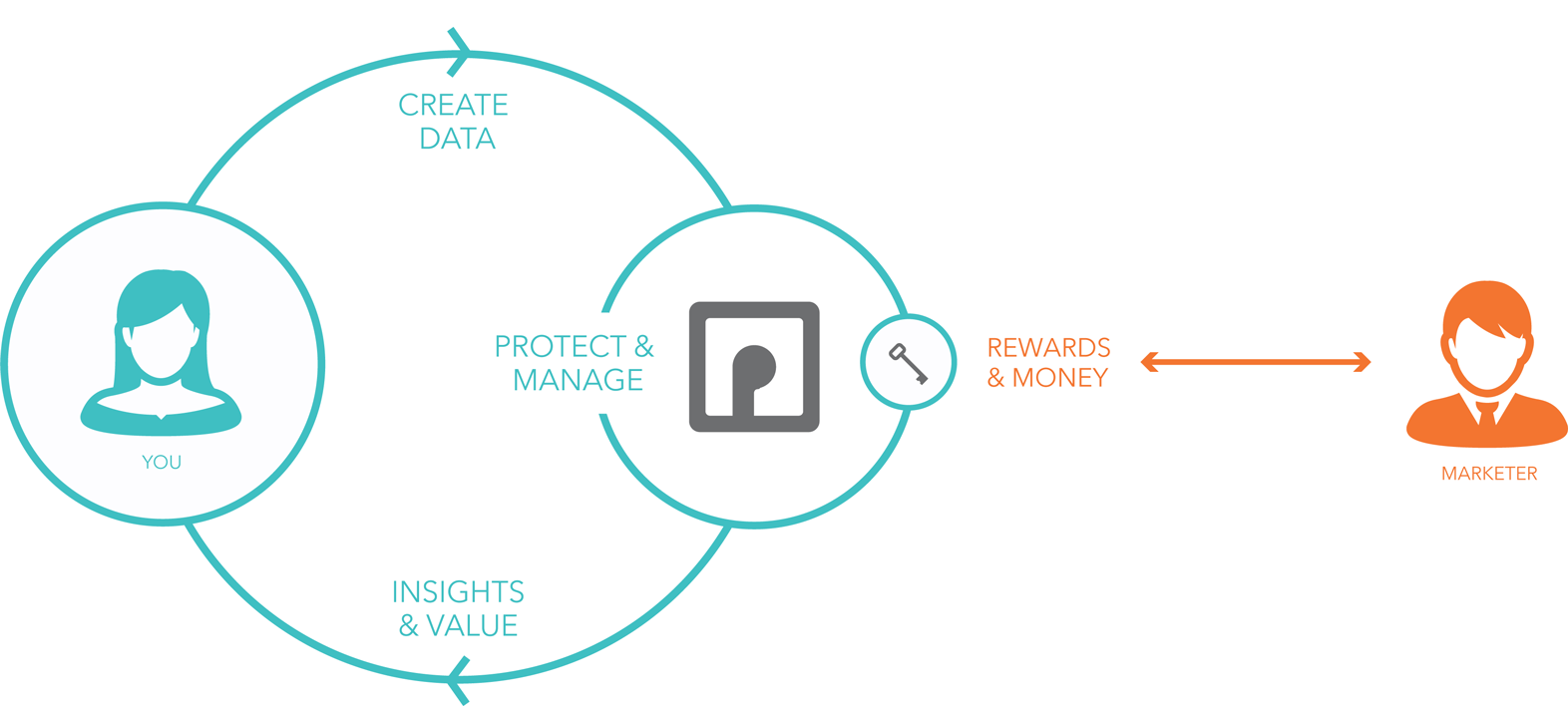
Here (and in New Zealand) we not only have lots of VRM developers (Flamingo, Fourth Party, Geddup, Meeco, MyWave, OneExus, Welcomer and others I’ll insulting by not listing yet), but legal easement toward proving that individuals can do the more with their own data than can the companies that follow us. And proving as well that individuals managing their own data will be good for those companies as well. The data they get will be richer, more accurate, more contextual, and more useful.
This challenge is not new. It’s as old as our species. The biggest tech revolutions have always been inventions individuals could put to the best use:
- Stone tools
- Weaving
- Smithing
- Musical instruments
- Hand-held hunting and fighting tools
- Automobiles
- PCs
- The Internet (which is a node-to-node invention, not an advanced phone or cable company, even though we pay those things for access to it)
- Mobile phones and tablets
- Movable type (which would be nowhere without individual authors — and writing tools in the hands of those authors)
There should be symbiosis here. There are things big organizations do best, and things individuals do best. And much that both do best when they work together.
Look at cars, which are a VRM technology: we use them to get around the marketplace, and to help us do business with many companies. They give us ways to be both independent and engaging. But companies don’t drive them. We do. Companies provide parking lots, garages, drive-up windows and other conveniences for drivers. Symbiosis.
So, while Telstra is great at building and managing communication infrastructure and services, its customers will be great at doing useful stuff with the kind of data Ben requested, such as locations, calls and texts — especially after customers get easy-to-use tools and services that help them work as points of integration for their own data, and managers of what gets done with it. There are many VRM developers working toward that purpose, around the world, And many more that will come once they smell the opportunities.
These opportunities are only apparent when you look at the market through your own eyes as a sovereign human being. The same opportunities are mostly invisible when you look at the market from the eye at the top of the industrial pyramid.
Bonus links:
- Hugh McLeod, who drew the cartoon at the top for me way back in 2004.
- Why we need first person technologies on the Net
- Making customer experience a first-person thing
- Up next: a master app to help customers scale
- Capgemini on VRM
- State of the VRooM 2014
* My understanding is that privacy principles such as the OECD’s and Ontario’s provide guidance but not the full force of law, or means of enforcement. Australia’s differ because they have teeth. See the Determination on page 36 of the Privacy Commissioner’s investigation and decision. Canada’s also has teeth. See the list of orders issued in Ontario. If there are other examples of decisions like this one, anywhere in the world, please let us know.


 Meerkat
Meerkat Periscope
Periscope





 United
United  Doc Searls
Doc Searls 

 is a piece by
is a piece by