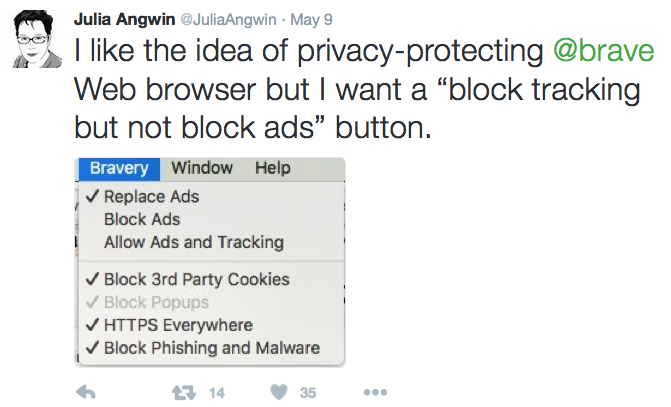
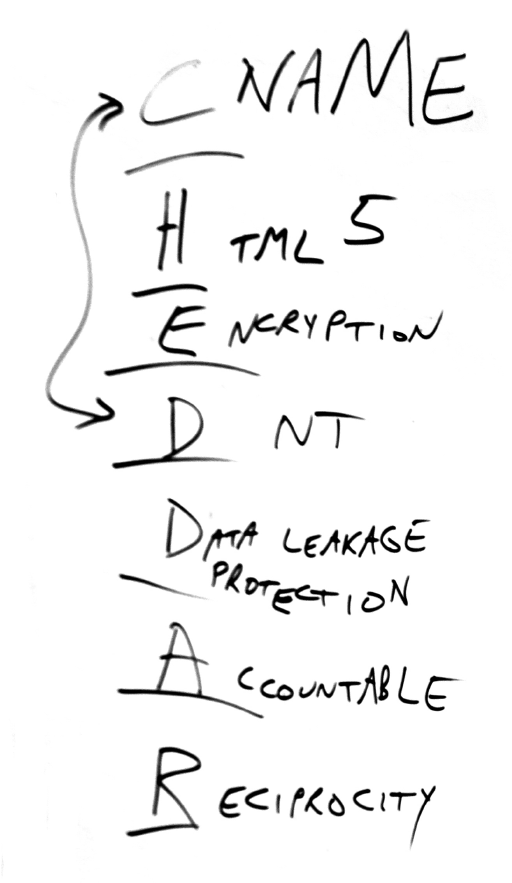
This is a comment I couldn’t publish under this post before my laptop died. (Fortunately I sent it to my wife first, so I’m posting it here, from her machine.)
OMMA’s theme is “Humanizing the Great Ad Machine” Good one. Unfortunately, the agenda and speaker list suggest that industry players are the only ones in a position to do that. They aren’t..
The human targets of the Great Ad Machine are actually taking the lead—by breaking it.
Starting with ad blocking and tracking protection.
I see no evidence of respect for that fact, however, in the posts and tweets (at #MPOMMA) coming out of the conference so far. Maybe we can change that.
Let’s start by answering the question raised by the headline in Ad Blocking and DVRs: How Similar? I can speak as an operator of both technologies, and as a veteran marketer as well. So look at the rest of this post as the speech I’d give if I was there at OMMA…
Ad blocking and DVRs have four main things in common.
1) They are instruments of personal independence;
2) They answer demand for avoiding advertising. That demand exists because most advertising wastes time and space in people’s lives, and people value those two things more than whatever good advertising does for the “content” economy;
3) Advertising agents fail to grok this message; which is why—
4) Advertising agents and the “interactive” ad industry cry foul and blame the messengers (including the makers of ad blockers and other forms of tracking protection), rather than listening to, or respecting, what the market tells them, loudly and clearly.
Wash, rinse and repeat.
The first wash was VCRs. Those got rinsed out by digital TV. The second wash was DVRs. Those are being rinsed out right now by the Internet. The third wash is ad blocking.
The next rinse will happen after ad blocking succeeds as chemo for the cancer of ads that millions on the receiving end don’t want.
The next wash will be companies spending their marketing money on listening for better signals of demand from the marketplace, and better ways of servicing existing customers after the sale.
This can easily happen because damn near everybody is on the Net now, or headed there. Not trapped on TV or any other closed, one-way, top-down, industry-controlled distribution system.
On the Net, everybody has a platform of their own. There is no limit to what can be built on that platform, including much better instruments for expressing demand, and much better control over private personal spaces and the ways personal data are used by others. Ad blocking is just the first step in that direction.
The adtech industry (including dependent publishers) can come up with all the “solutions” they want to the ad blocking “problem.” All will fail, because ad blocking is actually a solution the market—hundreds of millions of real human beings—demands. Every one of adtech’s “solutions” is a losing game of whack-a-mole where the ones with hammers bang their own heads.
For help looking past that game, consider these:
1) The Interent as we know it is 21 years old. Commercial activity on it has only been possible since April 30, 1995. The history of marketing on the Net since then has been a series of formative moments and provisional systems, not a permanent state. In other words, marketing on the Net isn’t turtles all the way down, it’s scaffolding. Facebook, Google and the rest of the online advertising world exist by the grace of provisional models that have been working for only a few years, and can easily collapse if something better comes along. Which it will. Inevitably. Because…
2) When customers can signal demand better than adtech can manipulate it or guess at it, adtech will collapse like a bad soufflé.
3) Plain old brand advertising, which has always been aimed at populations rather than people, isn’t based on surveillance, and has great brand-building value, will carry on, free of adtech, doing what only it can do. (See the Ad Contrarian for more on that.)
In the long run (which may be short) winners will be customers and the companies that serve them respectfully. Not more clueless and manipulative surveillance-based marketing schemes.
Winning companies will respect customers’ independence and intentions. Among those intentions will be terms that specify what can be done with shared personal data. Those terms will be supplied primarily by customers, and companies will agree to those terms because they will be friendly, work well for both sides, and easily automated.
Having standard ways for signaling demand and controlling use of personal data will give customers the same kind of scale companies have always had across many customers. On the Net, scale can work in both directions.
Companies that continue to rationalize spying on and abusing people, at high costs to everybody other than those still making hay while the sun shines, will lose. The hay-makers will also lose as soon as the light of personal tolerance for abuse goes out, which will come when ad blocking and tracking protection together approach ubiquity.
But the hay-makers can still win if they start listening to high-value signals coming from customers. It won’t be hard, and it will pay off.
The market is people, folks. Everybody with a computer or a smart mobile device is on the Net now. They are no longer captive “consumers” at the far ends of one-way plumbing systems for “content.” The Net was designed in the first place for everybody, not just for marketers who build scaffolding atop customer dislike and mistake it for solid ground.
It should also help to remember that the only business calling companies “advertisers” is advertising. No company looks in the mirror and sees an advertiser there. That’s because no company goes into business just so they can advertise. They see a car maker, a shoe store, a bank, a brewer, or a grocer. Advertising is just overhead for them. I learned this lesson the hard way as a partner for 20 years in a very successful ad agency. Even if our clients loved us, they could cut their ad budget to nothing in an instant, or on a whim.
There’s a new world of marketing waiting to happen out there in the wide-open customer-driven marketplace. But it won’t grow out of today’s Great Ad Machine. It’ll grow out of new tech built on the customers’ side, with ad blocking and tracking protection as the first examples. Maybe some of that tech is visible at OMMA. Or at least maybe there’s an open door to it. If either is there, let’s see it. Hashtag: #VRM. (For more on that, see https://en.wikipedia.org/wiki/Vendor_relationship_management.)
If not, you can still find developers here .









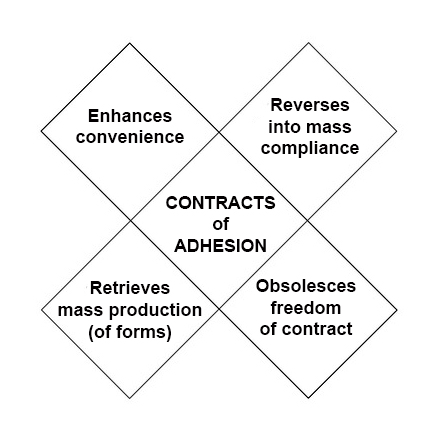
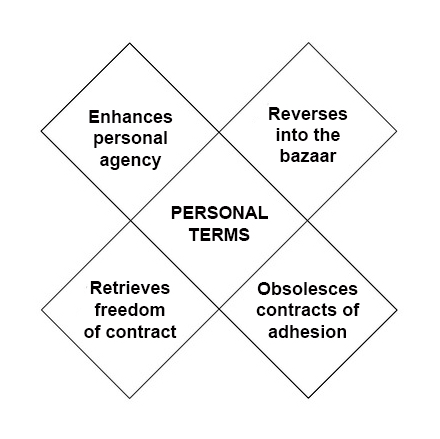
 The
The difference between Phase One and Phase Two is
difference between Phase One and Phase Two is  Next steps in tracking protection and ad blocking. At the last VRM Day and IIW, we discussed
Next steps in tracking protection and ad blocking. At the last VRM Day and IIW, we discussed