Even if you’re on a phone, chances are you’re reading this in a browser.
Chances are also that most of what you do online is through a browser.
Hell, many—maybe even most—of the apps you use on your phone use the Webkit browser engine. Meaning they’re browsers too.
And, of course, I’m writing this in a browser.
Which, alas, is subordinate by design. That’s because, while the Internet at its base is a word-wide collection of peers, the Web that runs on it is a collection of servers to which we are mere clients. The model is an old mainframe one called client-server. This is actually more of a calf-cow arrangement than a peer-to-peer one:

The reason we don’t feel like cattle is that the base functions of a browser work fine, and misdirect us away from the actual subordination of personal agency and autonomy that’s also taking place.
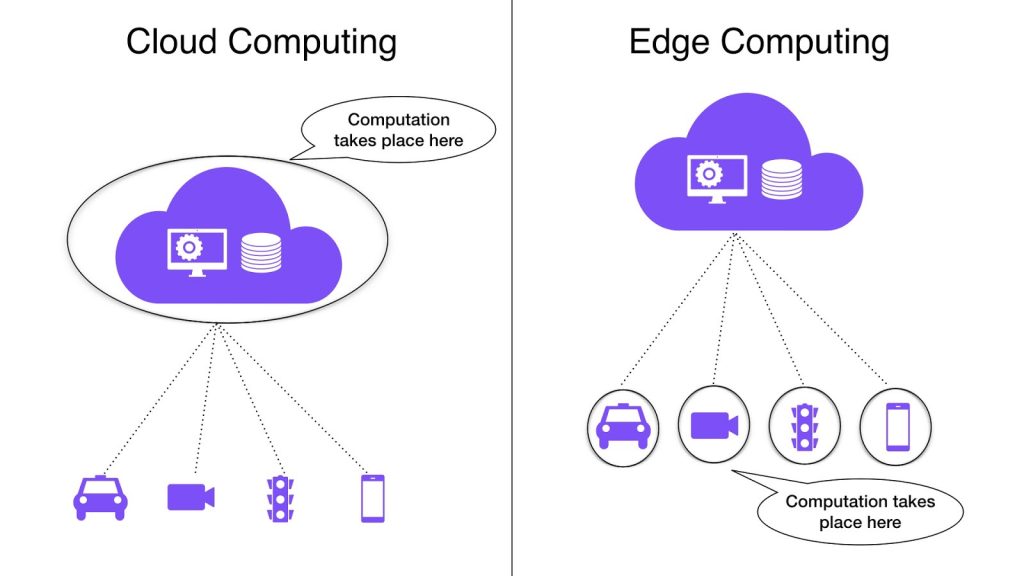
See, the Web invented by Tim Berners-Lee was just a way for one person to look at another’s documents over the Internet. And that it still is. When you “go to” or “visit” a website, you don’t go anywhere. Instead, you request a file. Even when you’re watching or listening to an audio or video stream, what actually happens is that a file unfurls itself into your browser.
What you typically expect when you go to a website is typically the file called a page. You also expect that page will bring a payload of other files: ones providing graphics, video clips, or whatever. You might also expect the site to remember that you’ve been there before, or that you’re a subscriber to the site’s services.
You may also understand that the site remembers you because your browser carries a “cookie” the site put there, to helps the site remember what’s called “state,” so the browser and the site can renew their acquaintance with every visit. It is for this simple purpose that Lou Montulli invented the cookie in the first place, back in 1994. Lou got that idea because the client-server model puts the most agency on the server’s side, and in the dial-up world of the time, that made the most sense.
Alas, even though we now live in a world where there can be boundless intelligence on the individual’s side, and there is far more capacious communication bandwidth between network nodes, damn near everyone continues to presume a near-absolute power asymmetry between clients and servers, calves and cows, people and sites. It’s also why today when you go to a site and it asks you to accept its use of cookies, something unknown to you (presumably—you can’t tell) remembers that “agreement” and its settings, and you don’t—even though there is no reason why you shouldn’t or couldn’t. It doesn’t even occur to the inventors and maintainers of cookie acceptance systems that a mere “user” should have a way to record, revisit or audit the “agreement.” All they want is what the law now requires of them: your “consent.”
This near-absolute power asymmetry between the Web’s calves and cows is also why you typically get a vast payload of spyware when your browser simply asks to see whatever it is you actually want from the website. To see how big that payload can be, I highly recommend a tool called PageXray, from Fou Analytics, run by Dr. Augustine Fou (aka @acfou). For a test run, try PageXray on the Daily Mail’s U.S. home page, and you’ll see that you’re also getting this huge payload of stuff you didn’t ask for:
Adserver Requests: 756
Tracking Requests: 492
Other Requests: 184
The visualization looks like this:

This is how, as Richard Whitt perfectly puts it, “the browser is actually browsing us.”
All those requests, most of which are for personal data of some kind, come in the form of cookies and similar files. The visual above shows how information about you spreads out to a nearly countless number of third parties and dependents on those. And, while these cookies are stored by your browser, they are meant to be readable only by the server or one or more of its third parties.
This is the icky heart of the e-commerce “ecosystem” today.
By the way, and to be fair, two of the browsers in the graphic above—Epic and Tor—by default disclose as little as possible about you and your equipment to the sites you visit. Others have privacy features and settings. But getting past the whole calf-cow system is the real problem we need to solve.
Cross-posted at the Customer Commons blog, here.







 From the
From the