Those are the three market conversations happening in the digital publishing world. Let’s look into what they’re saying, and then what more they can say that’s not being said yet.
A: Publisher-Reader
Publishing has mostly been a push medium from the start. One has always been able to write back to The Editor, and in the digital world one can tweet and post in other places, including one’s own blog. But the flow and power asymmetry is still push-dominated, and the conversation remains mostly a one-way thing, centered on editorial content. (There is also far more blocking of ads than talk about them.)
An important distinction to make here is between subscription-based pubs and free ones. The business model of subscription-supported pubs is (or at least includes) B2C: business-to-customer. The business model of free pubs is B2B: business-to-business. In the free pub case, the consumer (who is not a customer, because she isn’t paying anything) is the product sold to the pub’s customer, the advertiser.
Publishers with paying subscribers have a greater stake — and therefore interest — in opening up conversation with customers. I believe they are also less interested in fighting with customers blocking ads than are the free pubs. (It would be interesting to see research on that.)
B. Publisher-Advertiser
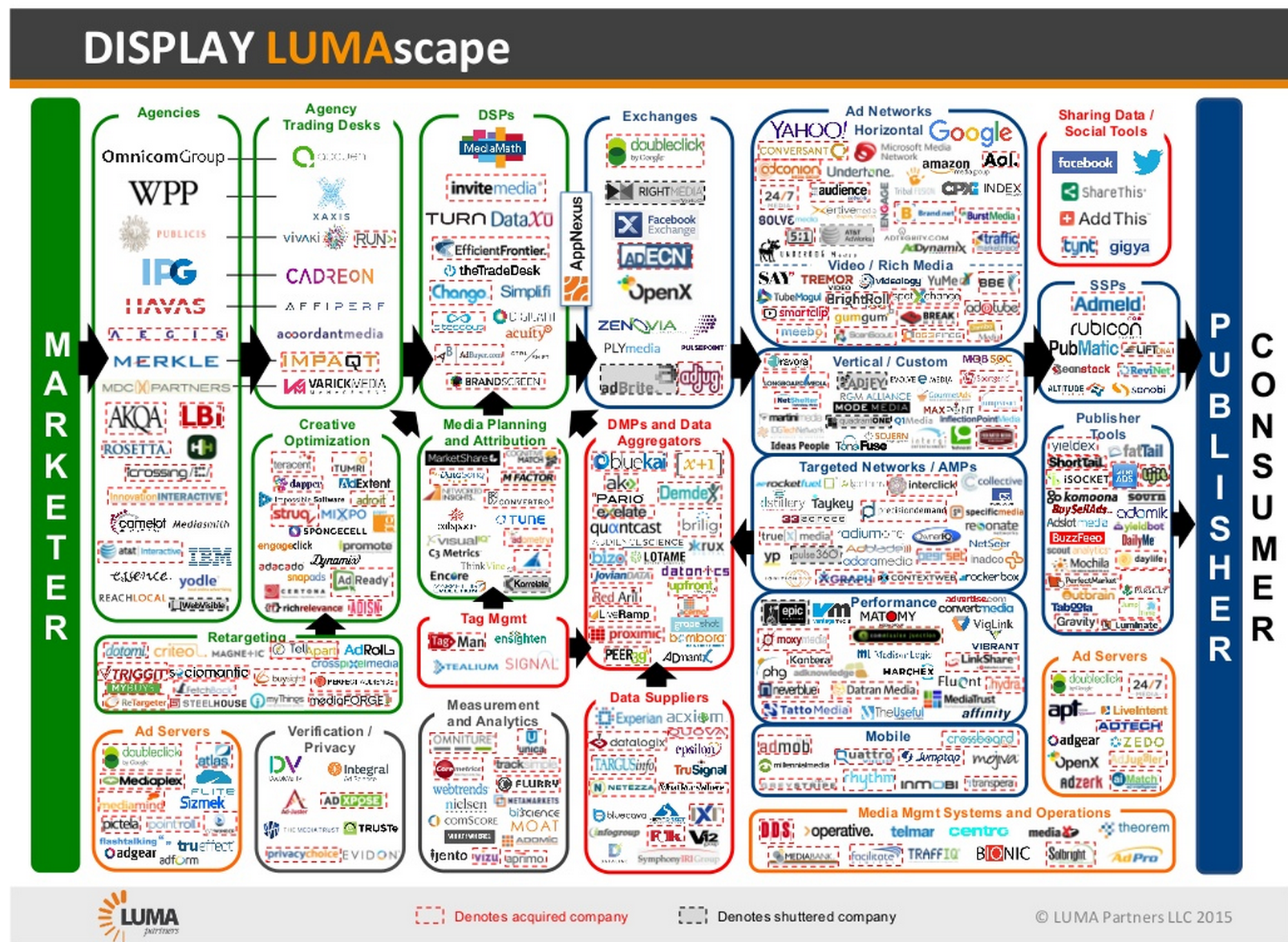
In the offline world, this was an uncomplicated thing. Advertisers or their agencies placed ads in publications, and paid directly for it. In the online world, ads come to publishers through a tangle of intermediaries:
 :
:
Thus publishers may have no idea at any given time what ads get placed in front of what readers, or for what reason. In service to this same complex system, they also serve up far more than the pages of editorial content that attracts readers to the site. Sight unseen, they plant tracking cookies and beacons in readers’ browsers, to follow those readers around and report their doings back to third parties that help advertisers aim ads back at those readers, either on the publisher’s site or elsewhere.
We could explore the four-dimensional shell game that comprises this system, but for our purposes here let’s just say it’s a B2B conversation. That it’s a big one now doesn’t mean it has to be the only one. Many others are possible.
C. Reader-Advertiser
In traditional offline advertising, there was little if any conversation between readers and advertisers, because the main purpose of advertising was to increase awareness. (Or, as Don Marti puts it, to send an economic signal.) If there was a call to action, it usually wasn’t to do something that involved the publisher.
A lot of online advertising is still that way. But much of it is direct response advertising. This kind of advertising (as I explain in Separating Advertising’s Wheat and Chaff) is descended not from Madison Avenue, but from direct mail (aka junk mail). And (as I explain in Debugging adtech’s assumptions) it’s hard to tell the difference.
Today readers are speaking to advertisers a number of ways:
- Responding to ads with a click or some other gesture. (This tens to happen at percentages to the right of the decimal point.)
- Talking back, one way or another, over social media or their own blogs.
- Blocking ads, and the tracking that aims them.
Lately the rate of ad and tracking blocking by readers has gone so high that publishers and advertisers have been freaking out. This is characterized as a “war” between ad-blocking readers and publishers. At the individual level it’s just prophylaxis. At the group level it’s a boycott. Both ways it sends a message to both publishers and advertisers that much of advertising and the methods used for aiming it are not welcome.
This does not mean, however, that making those ads or their methods more welcome is the job only of advertisers and publishers. Nor does it mean that the interactions between all three parties need to be confined to the ones we have now. We’re on the Internet here.
The Internet as we know it today is only twenty years old: dating from the end of the NSFnet (on 30 April 1995) and the opening of the whole Internet to commercial activity. There are sand dunes older than Facebook, Twitter — even Google — and more durable as well. There is no reason to confine the scope of our invention to incremental adaptations of what we have. So let’s get creative here, and start by looking at, then past, the immediate crisis.
People started blocking ads for two reasons: 1) too many got icky (see the Acceptable Ads Manifesto for a list of unwanted types); 2) unwelcome tracking. Both arise from the publisher-advertiser conversation, which to the reader (aka consumer) looks like this:
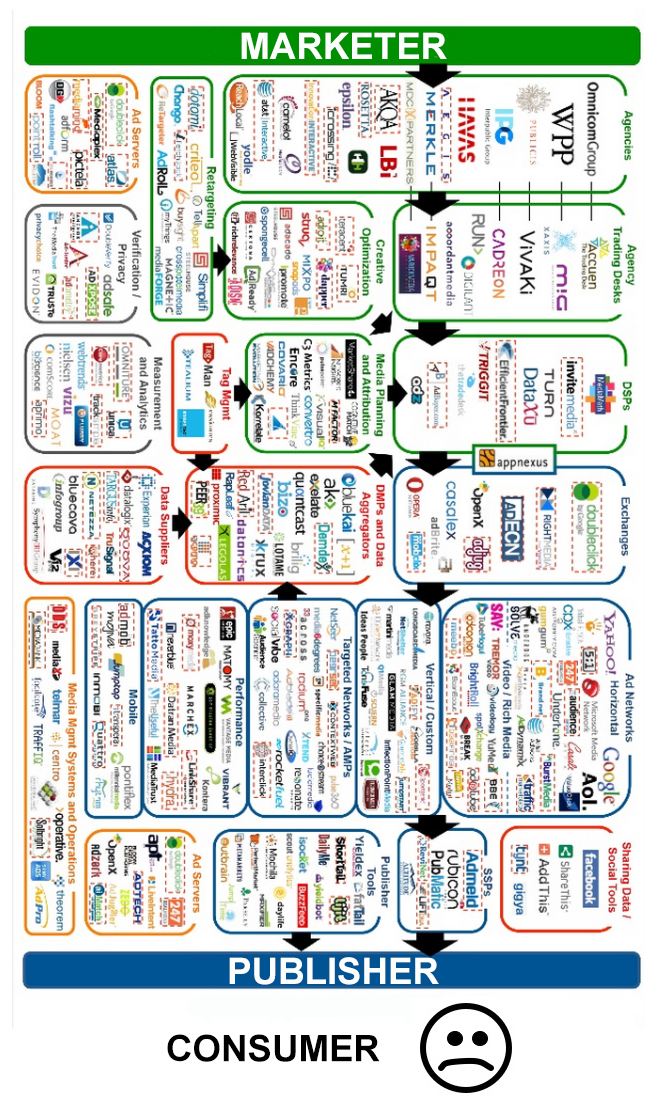
Thus the non-conversation between readers blocking ads and both publishers and advertisers (A and C) looks like this:

So far.
Readers also have an interest in the persistence of the publishers they read. And they have an interest in at least some advertisers’ goods and services, or the marketplace wouldn’t exist.
Thus A and C are conversational frontiers — while B is a mess in desperate need of cleaning up.
VRM is about A and C, and it can help with B. It also goes beyond conversation to include the two other activities that comprise markets: transaction and relationship. You might visualize it as this:

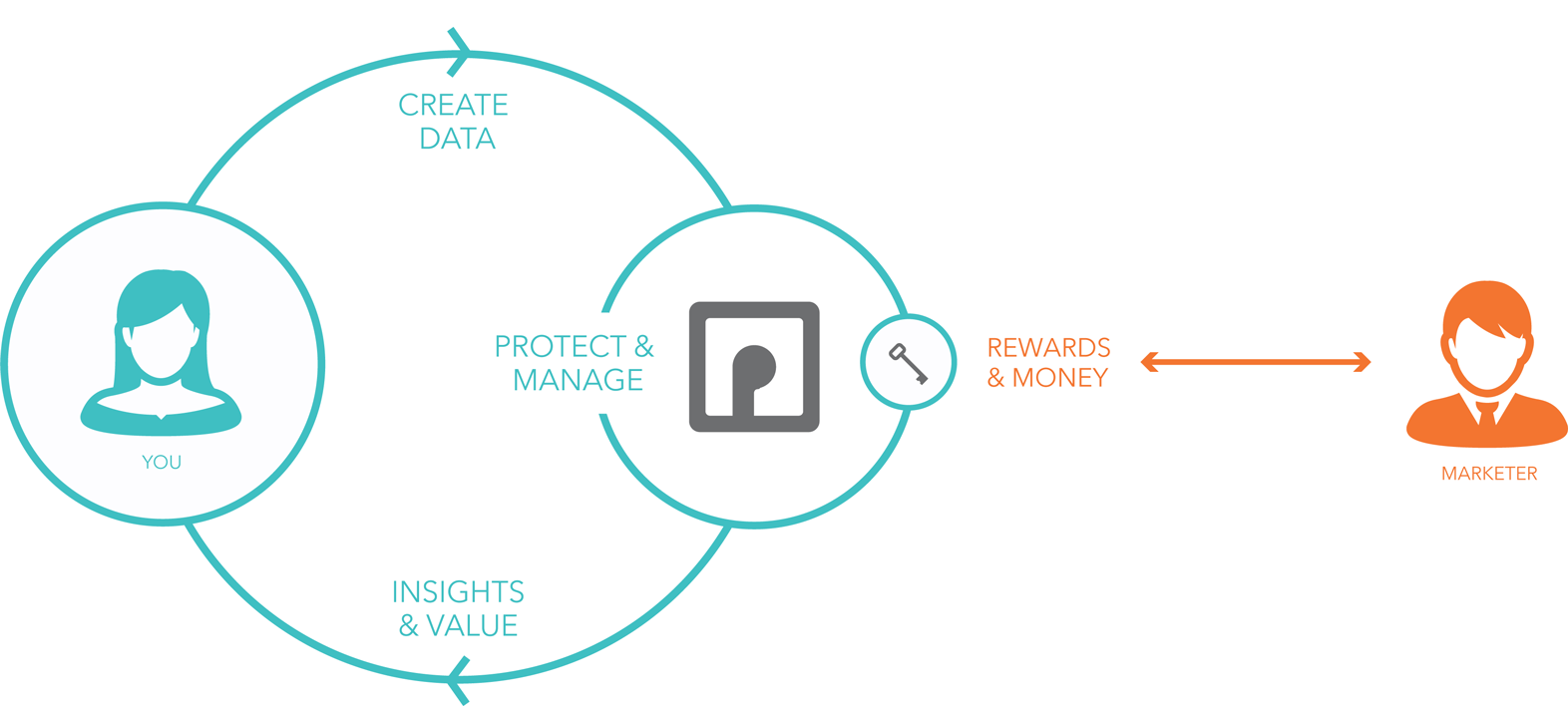
From Turning the customer journey into a virtuous cycle:
One of the reasons we started ProjectVRM is that actual customers are hard to find in the CRM business. We are “leads” for Sales, “cases” in Support, “leads” again in Marketing. At the Orders stage we are destinations to which products and invoices are delivered. That’s it.
Oracle CRM, however, has a nice twist on this (and thanks to @nitinbadjatia of Oracle for sharing it*):

Here we see the “customer journey” as a path that loops between buying and owning. The blue part — OWN, on the right — is literally the customer’s own-space. As the text on the OWN loop shows, the company’s job in that space is to support and serve. As we see here…
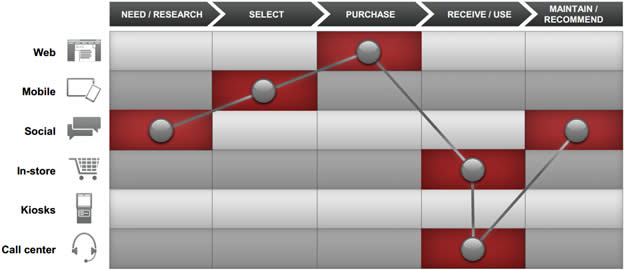
… the place where that happens is typically the call center.
Now let’s pause to consider the curb weight of “solutions” in the world of interactivity between company and customer today. In the BUY loop of the customer journey, we have:
- All of advertising, which Magna Global expects to pass $.5 trillion this year
- All of CRM, which Gartner pegs at $18b)
- All the rest of marketing, which has too many segments for me to bother looking up
In the OWN loop we have a $0trillion greenfield. This is where VRM started, with personal data lockers, stores, vaults, services and (just in the last few months) clouds.
Now look around your home. What you see is mostly stuff you own. Meaning you’ve bought it already. How about basing your relationships with companies on those things, rather than over on the BUY side of the loop, where you are forced to stand under a Niagara of advertising and sales-pitching, by companies and agencies trying to “target” and “acquire” you. From marketing’s traditional point of view (the headwaters of that Niagara), the OWN loop is where they can “manage” you, “control” you, “own” you and “lock” you in. To see one way this works, check your wallets, purses, glove compartments and kitchen junk drawers for “loyalty” cards that have little if anything to do with genuine loyalty.
But what if the OWN loop actually belonged to the customer, and not to the CRM system? What if you had VRM going there, working together with CRM, at any number of touch points, including the call center?
So here are two questions for the VRM community:
- What are we already doing in those areas that can help move forward in A and B?
- What can we do that isn’t being done now?
Among things we’re already doing are:
- Maintaining personal clouds (aka vaults, lockers, personal information management systems, et.al.) from which data we control can be shared on a permitted basis with publishers and companies that want to sell us stuff, or with which we already enjoy relationships.
- Employing intelligent personal assistants of our own.
- Intentcasting, in which we advertise our intentions to buy (or seek services of some kind).
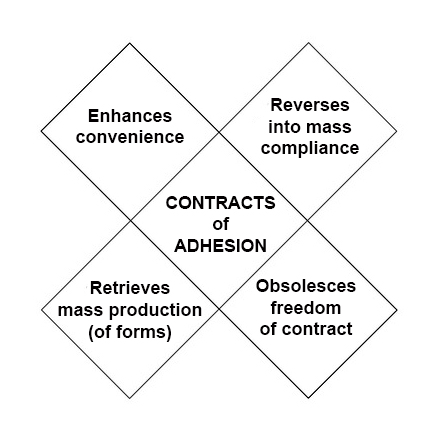
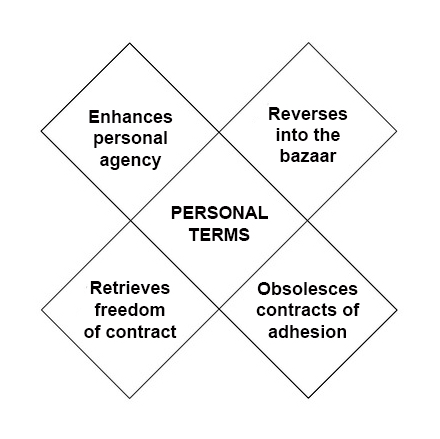
- Terms individuals can assert, to start basing interactions and relationships on equal power, rather than the defaulted one-way take-it-or-leave-it non-agreements we have today.
The main challenge for publishers and advertisers is to look outside the box in which their B2B conversation happens — and the threats to that box they see in ad blocking — and to start looking at new ways of interacting with readers. And look for leadership coming from tool and service providers representing those readers. (For example, Mozilla.)
The main challenge for VRM developers is to provide more of those tools and services.
Bonus links for starters (again, I’ll add more):







 The
The 




{kind=link}